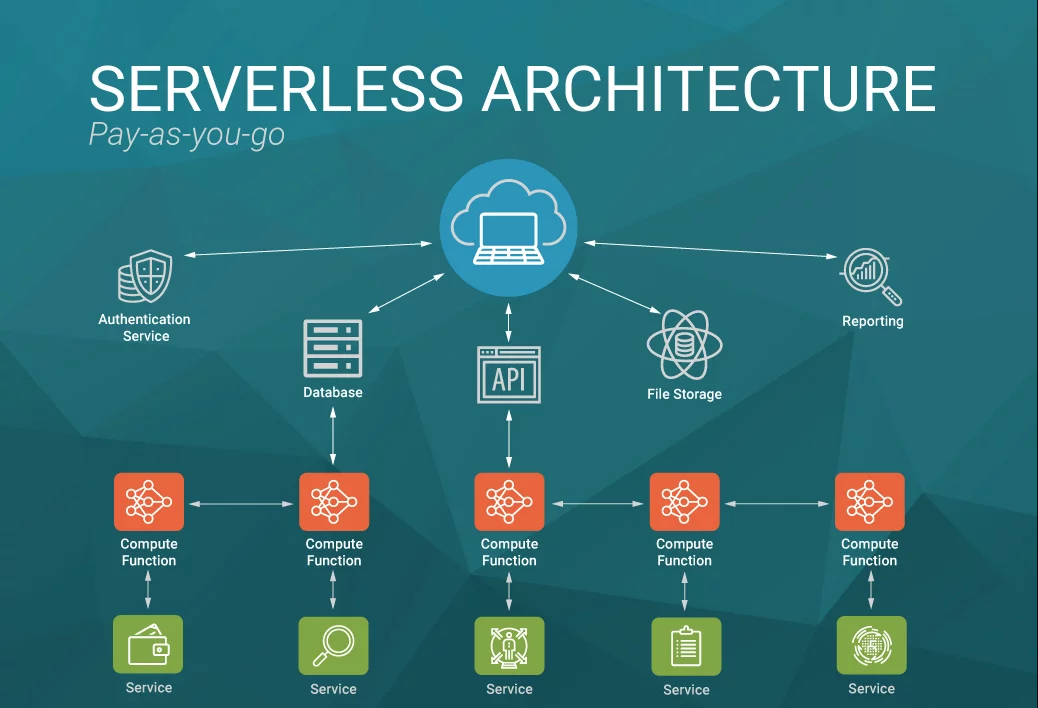
What is a serverless architecture?
A serverless architecture is a way to build and run applications and services without having to manage infrastructure. Serverless was first used to describe applications that significantly or fully incorporate third-party, cloud-hosted applications and services, to manage server-side logic and state. Application still runs on servers, but all the server management is done by AWS. By using a serverless architecture, developers can focus on their core product instead of worrying about managing and operating servers or runtimes, either in the cloud or on-premises. This reduced overhead lets developers reclaim time and energy that can be spent on developing great products which scale and that are reliable.
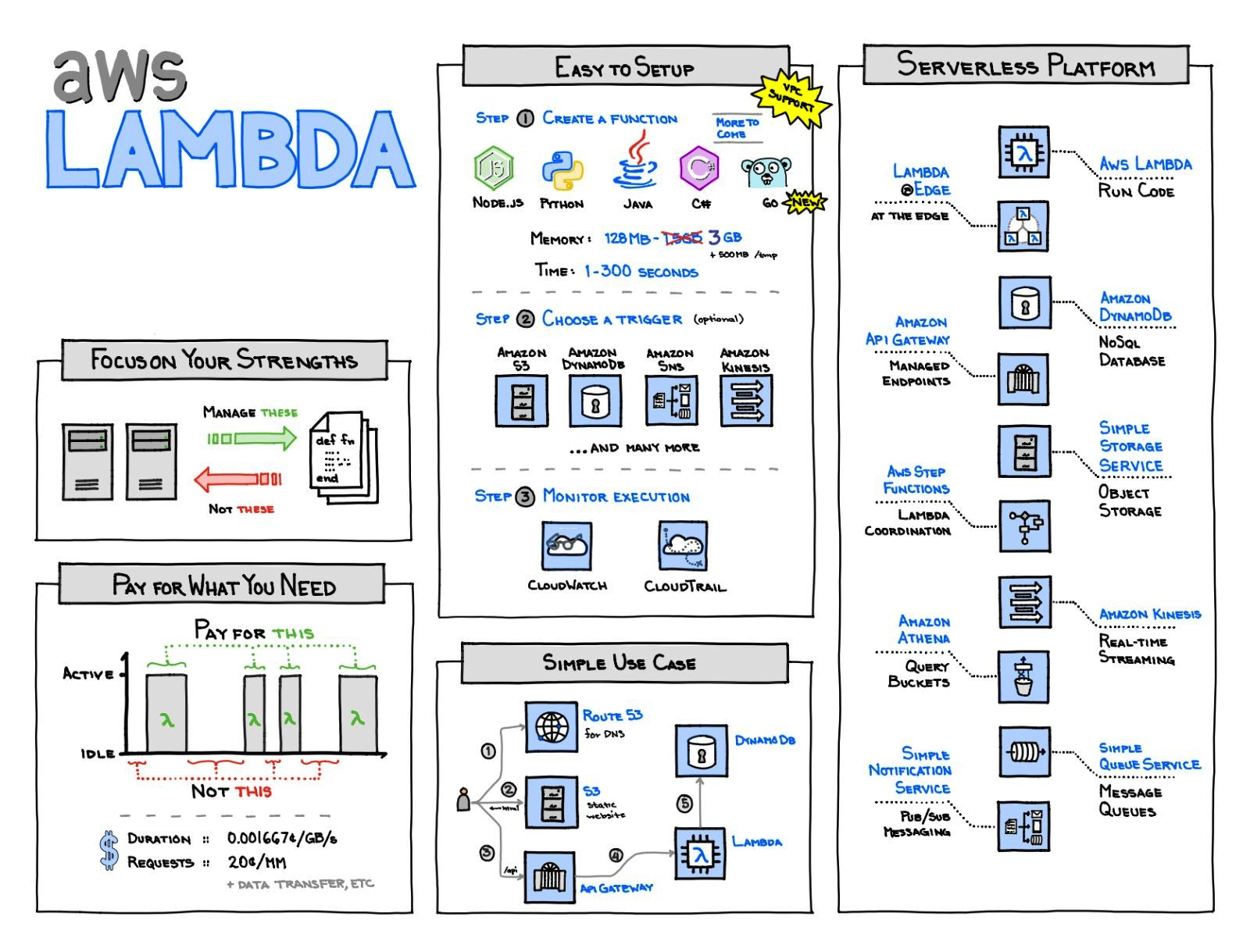
What is AWS Lambda?
AWS Lambda is a compute service that lets you run code without provisioning or managing servers. It executes code only when needed and scales automatically, from a few requests per day to thousands per second. You can use AWS Lambda to run your code in response to events, such as changes to data in an Amazon S3 bucket or an Amazon DynamoDB table, to run your code in response to HTTP requests using Amazon API Gateway or invoke your code using API calls made using AWS SDKs. There is no charge when code is not running. With Lambda, code can be runned for virtually any type of application or backend service. Lambda takes care of everything required to run and scale code with high availability.
What´s the idea?
The basic idea is to get the contact information for a specific person when someone types /contact and a name of the person in slack. The data must be reliable and should be stored only in one location.
How does it work?
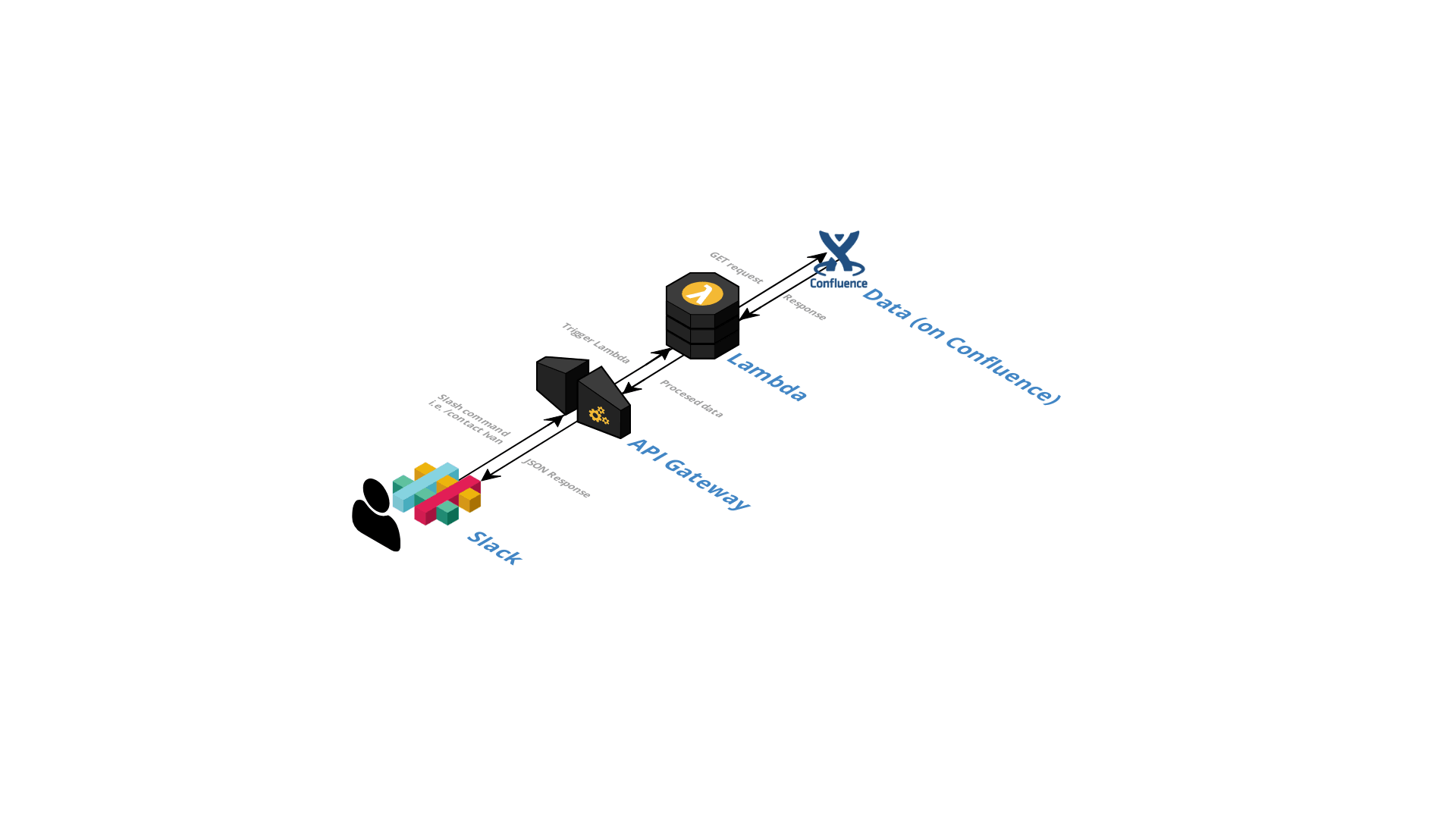
Firstly, we will start with the plugin logic. All of the used logic is written in NodeJS. Apart from NodeJS, supported languages in Lambda functions are Java, Python, GO and C#. In our case, we opted for NodeJS. The code is written locally and then uploaded to AWS because AWS doesn´t include all of the npm modules used when creating this plugin. For more info on creating deployment package click here. The logic is rather simple, the data is taken from the confluence page, parsed and then sent back to slack.
Used modules
Request module
The request module is used to retrieve the data from the confluence page. The instance is called with two parameters.
github:98e109229877aa7534353ef1c46bf0f6
Variable options contain information like url page from where the data is extracted, as well as authentication and certificate information
GetInfo is a function with three arguments
- error
- response
- data
Error contains information about possible errors that occurred while receiving data from the page. Response contains information such as response code received from the server hosting the page. The third argument is the most important one. In this example, it has the name HtmlBody but we can name it anyway we like. When getInfo function is called, the data from the page is stored in HtmlBody in html form.
Html-table-to-json module
The html-table-to-json module is used to transform the data from html form to JSON form. The module is defined with
shell:const HtmlTableToJson = require('html-table-to-json');
and an instance of the module is created with the
shell:const jsonTables = new HtmlTableToJson(HtmlBody);
JSON data form is stored in a variable jsonTabels and can be accessed by writing
shell:jsonTables['results'];
A sample data when typing jsonTables[‘results’][0] :
github:7ddaf4a932bf098886b86e561c33af79
The data is stored in a multidimensional array. The reason for it is to have access to multiple tables on one page and the data can be used from a specific table. The rest of the logic inside getInfo function searches and returns the specific data by some criteria thereby producing desired output.
How to connect slack to AWS Lambda?
To trigger the lambda from slack we need to create a slash command.
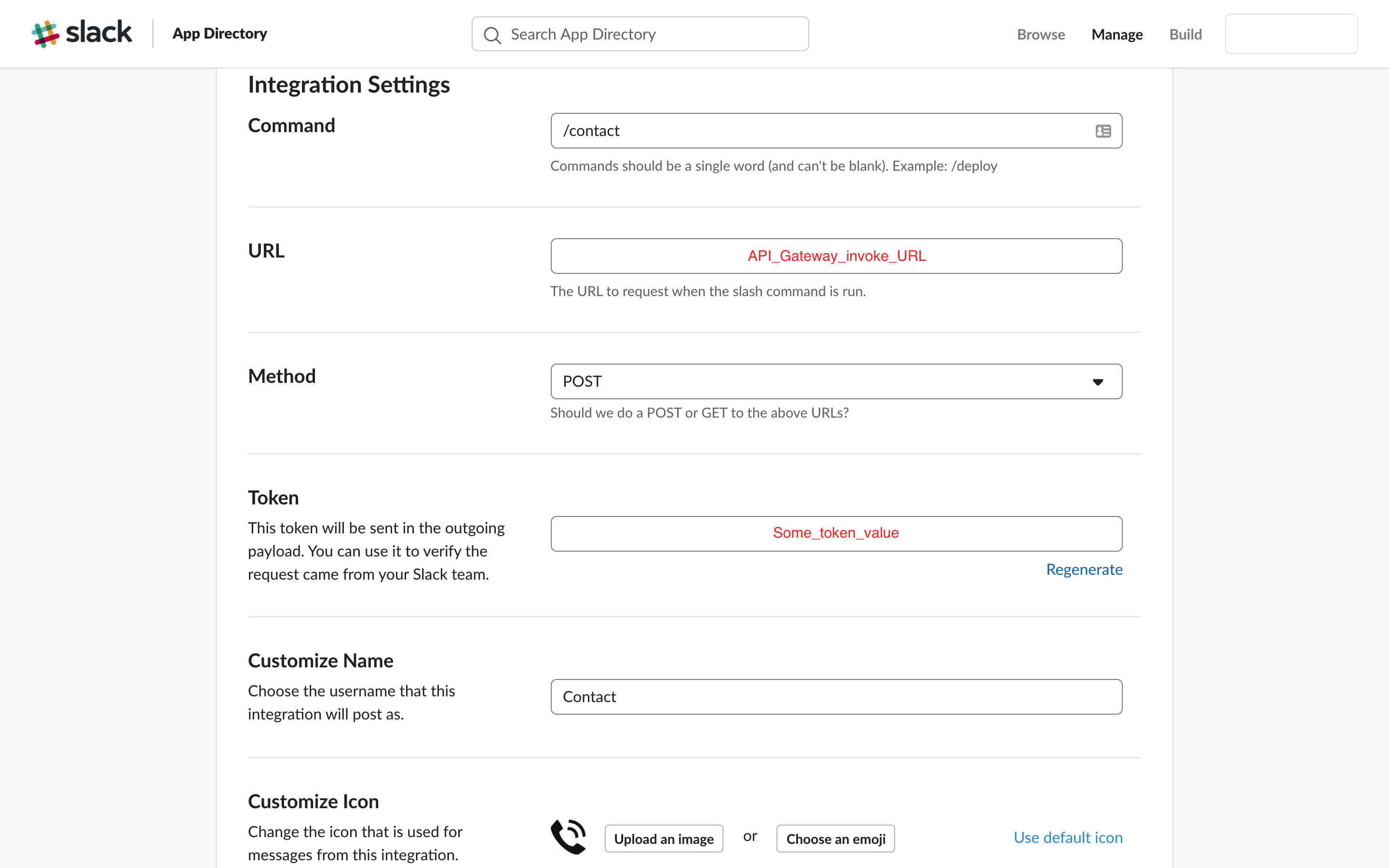
API Gateway is used to connect slack and lambda function. The invoke URL for API Gateway is written in the URL field when creating slash command. The code in lambda function is wrapped inside a handler
shell:exports.handler = (event, context, callback) => { … The rest of the code goes here … }
Slack sends a POST request to the API Gateway. The data from the slack is received and stored in an event.body. Example of data inside body when we type /contact some_user inside slack:
github:0837ad3cedfe89f1c45d0ece242ec7ca
The data is converted to JSON which provides key: value syntax.
github:e2ba0e52cbe7966b33ffb3065c778cdd
The value of a token inside the body is specific for a workspace inside slack and is used in the lambda function to add a security permission so only the users from that workspace or with that token value can trigger the lambda function. The criteria when searching for a specific person is the name of the person that is written after /contact. Slack takes the text after /contact and stores it in the body as a value of a field called text ( text = some_user in this example). When the data from the confluence is processed and the specific data is found, the lambda needs to send a response to slack.
Callback parameter is used to return the information to the caller.
shell:Callback (null, { statusCode: 200, body: outputData});
First callback parameter is an error and the second is an object result. Result contains status code and the output data which is returned to the caller in a string form.
How to add a feature of a clickable number
Slack has the ability to recognize if part of some text is a number and holds the appropriate format. Contact numbers should be written like ….xxx-xxxx.
Summary
When we trigger the slash command, the text after the name of the slash command is sent in the body of a POST request to the invoke URL of API Gateway. The body is stored in an event variable, parsed as a JSON. Token is used to authenticate the request and the text is used as a criteria when searching for the specific object. The information regarding users is retrieved from the confluence page with npm request module and transformed to JSON objects with html-table-to-json module. When the user matching the criteria is found, the data is returned to the caller with callback parameter.
