EINLEITUNG
Vor einem halben Jahr schrieb ich über das Aufsetzen von JIRA® Data Center mit Parallels Desktop. Wenn Sie die internen Details und Zusammenhänge bzgl. JIRA® Data Center erfahren wollen, sollten sie zuerst diesen Blog Post lesen. Ziel dieses Blog Posts ist es, zu zeigen, dass man mit Docker innerhalb von 5 Minuten ein funktionierendes JIRA® Data Center aufgesetzt bekommt.
Seit mehreren Jahren entwickle ich nun schon an einem JIRA Plugin und die nächste version wird offiziell JIRA® Data Center kompatibel sein. Doch jedesmal ist es ein riesen Aufwand sich eine Testumgebung aufzusetzen. Besonders während der Entwicklung brauche ich schnell mal ein frisches JIRA mit leerer Datenbank. Der Wunsch nach einer “Wegwerf-Testumgebung” war so groß, dass ich ein Cluster-Management Script geschrieben und vorgebaute Docker-Images im Dockerhub gepublished habe.
Beim Erstellen der Docker Images war es mir - wie bereits im BlogPost ‘Docker sicher und schlank einsetzen’ beschrieben - wichtig, dass die Container als non-root und mit dem gehärtetem Kernel unter Alpine-Linux laufen.
Das Cluster Management Script wollte ich vollständig in Bash schreiben, weil Bash auf den meisten Linux Systemen vorinstalliert ist. Es hat mich einiges an Kopfzerbrechen gekostet und wenn ich nochmal ein CLI Skript schreibe dann lieber in Python. Auf jedenfall irgendeine Sprache, die Funktionsrückgaben und Datentypen unterstützt. Aber genug davon, die propagierten fünf Minuten sind fast um, wir müssen uns sputen!
VORBEREITUNG
Das ganze ist mit detaillierter Anleitung auf GitHub zu finden:
https://github.com/codeclou/docker-atlassian-jira-data-center/tree/master/7.3.3
Wenn Sie es ausprobieren wollen, führen sie bitte die ‘Initial Configuration’ aus, so wie auf GitHub beschrieben.
CLUSTER ERZEUGEN
Sobald wir das Cluster Management Skript von GitHub installiert haben, können wir unser Cluster mit einem simplen Befehl erstellen.
shell:manage-jira-cluster-7.3.3.sh --action create --scale 1
Jetzt fährt erstmal eine JIRA Instanz, ein Loadbalancer und die PostgreSQL Datenbank hoch. Das Shared-Filesystem, das man normalerweise mit NFS umsetzt, wird mittels einer shared Docker-Volume umgesetzt.
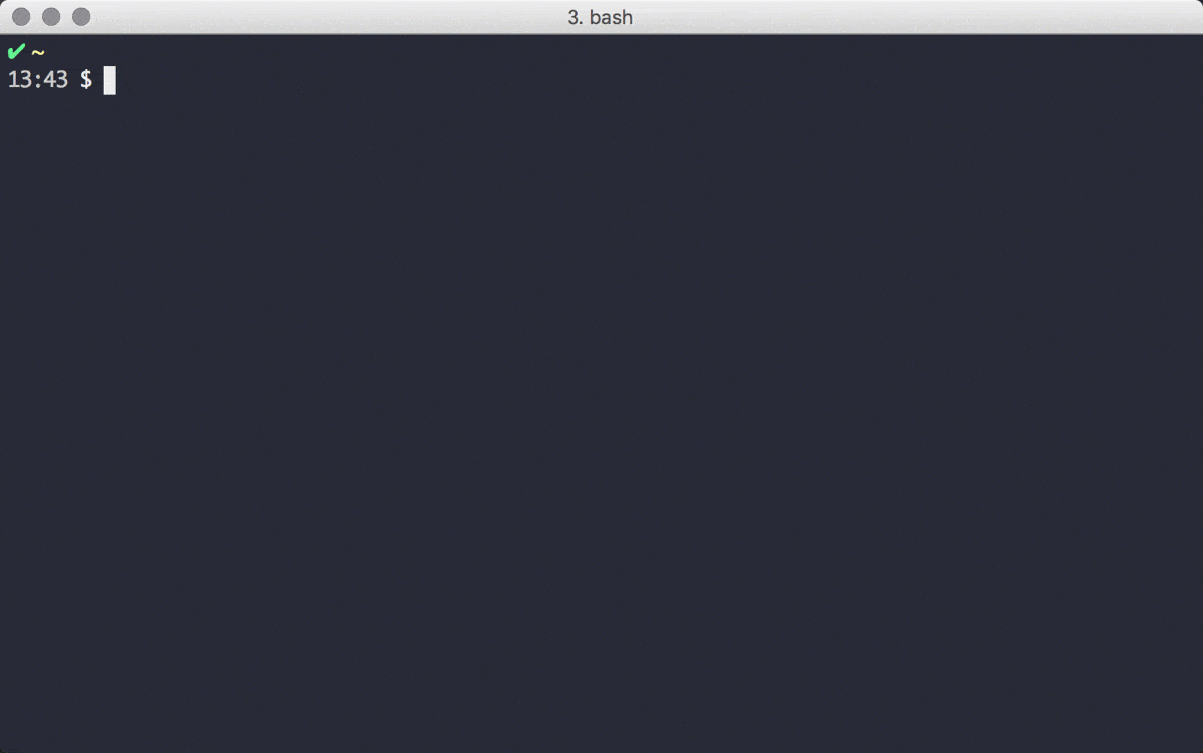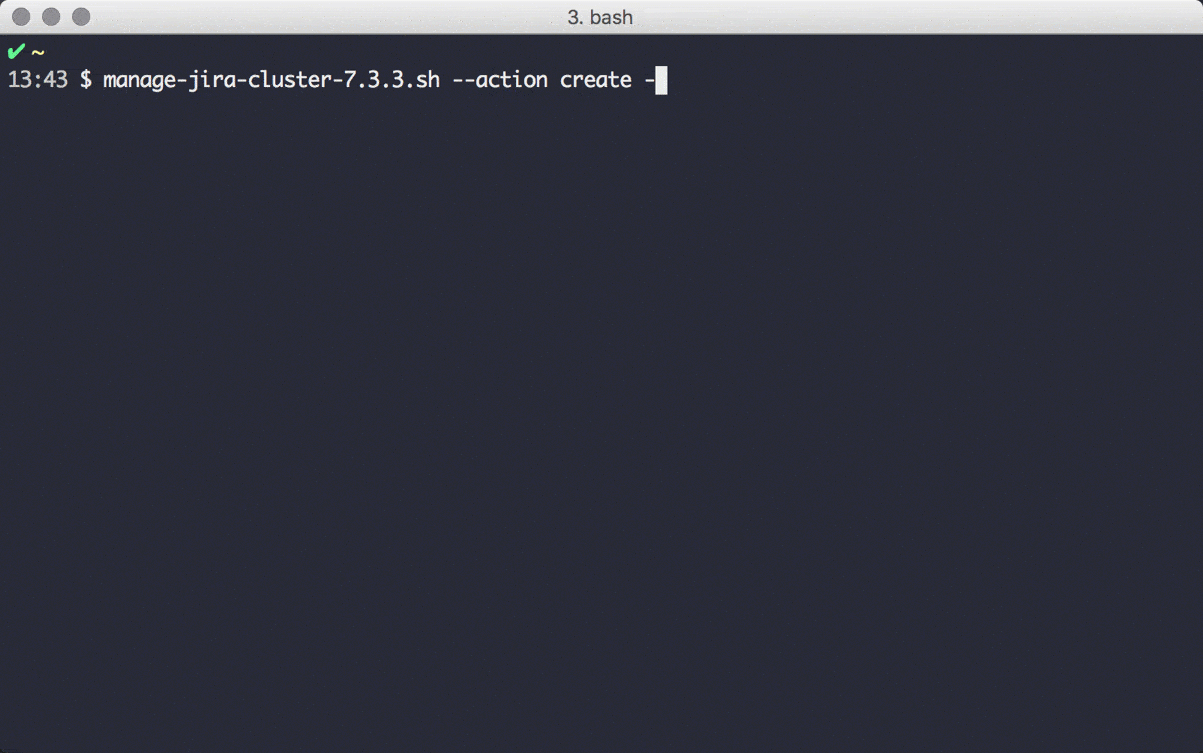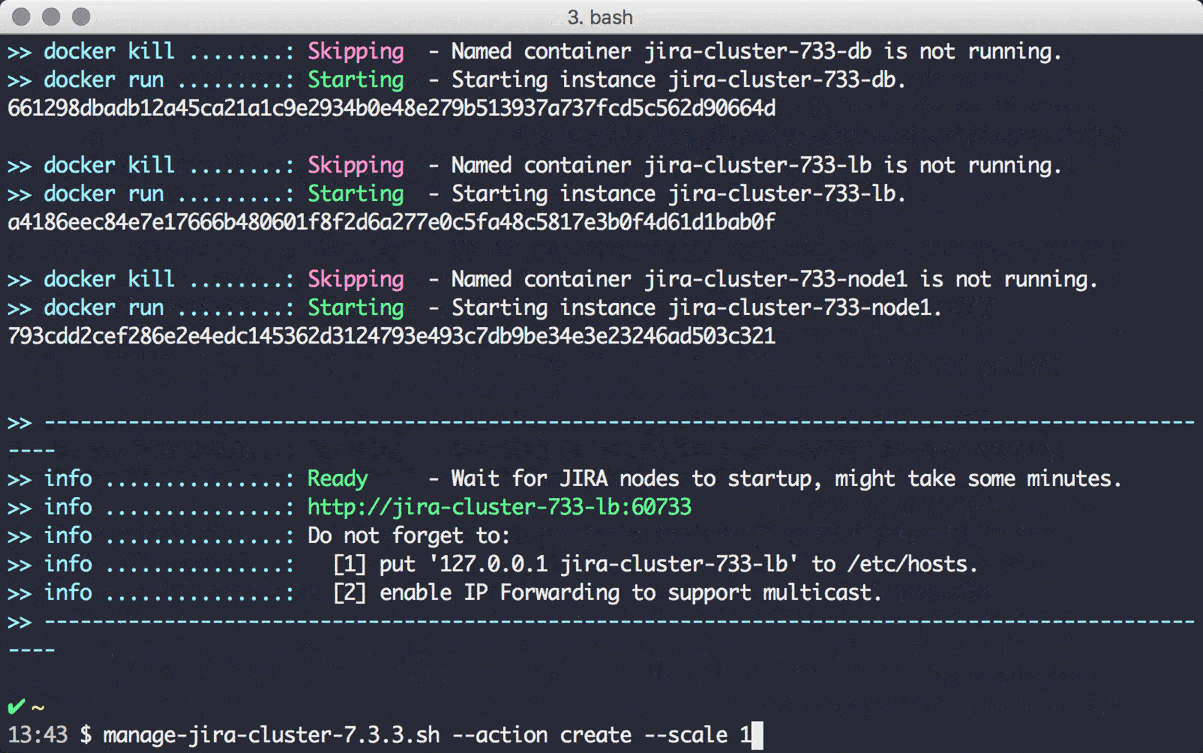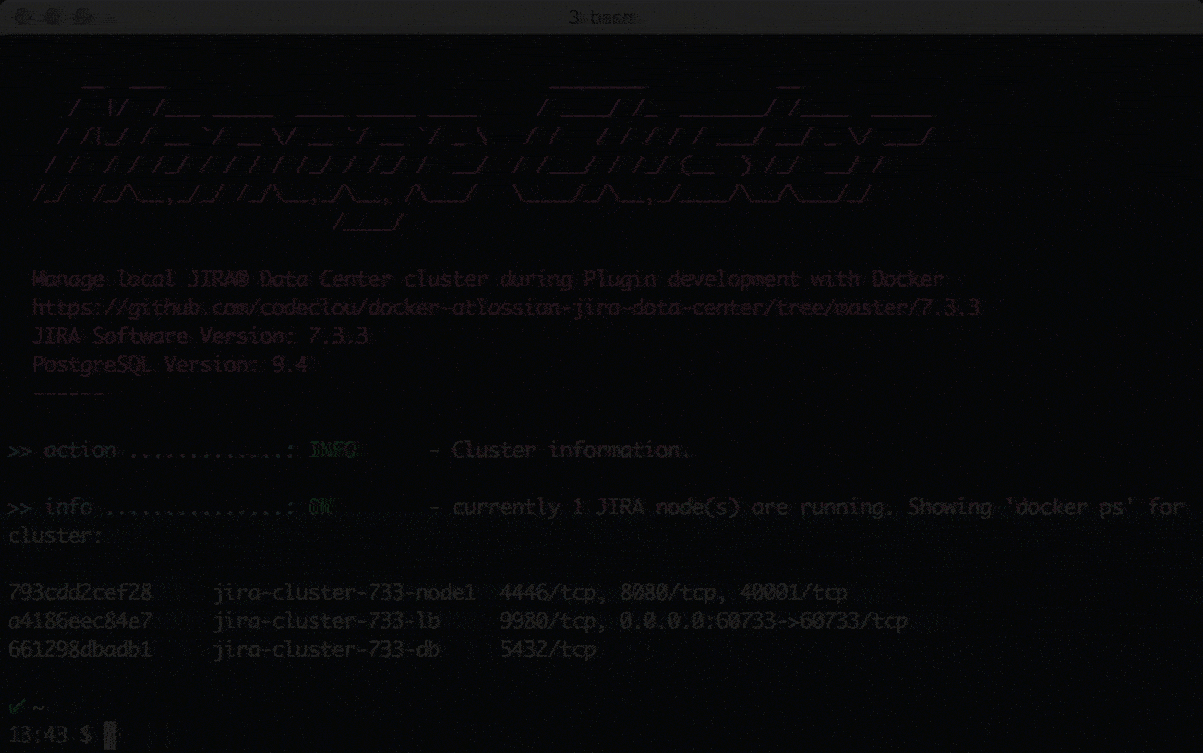
Sobald alles hochgefahren ist, schließen wir die Konfiguration der JIRA Instanz ab. Dazu gehen wir auf:
http://jira-cluster-733-lb:60733/
Wichtig ist, dass wir zuerst nur eine JIRA Instanz hochfahren, diese konfigurieren und im Anschluß das Cluster um weitere Instanzen erweitern. Wollen wir also insgesamt 5 JIRA Instanzen haben, so führen wir den folgenden Befehl aus.
shell:manage-jira-cluster-7.3.3.sh --action update --scale 5
Nun fahren weitere 4 Instanzen hoch. Das dauert alles immer einige Minuten. Loggt man sich nun in JIRA ein, und navigiert nach ‘System’ und ‘System Info’, so sollte man alle JIRA Instanzen als ‘Node state: Active’ sehen, wenn man nach ‘Cluster Nodes’ sucht.
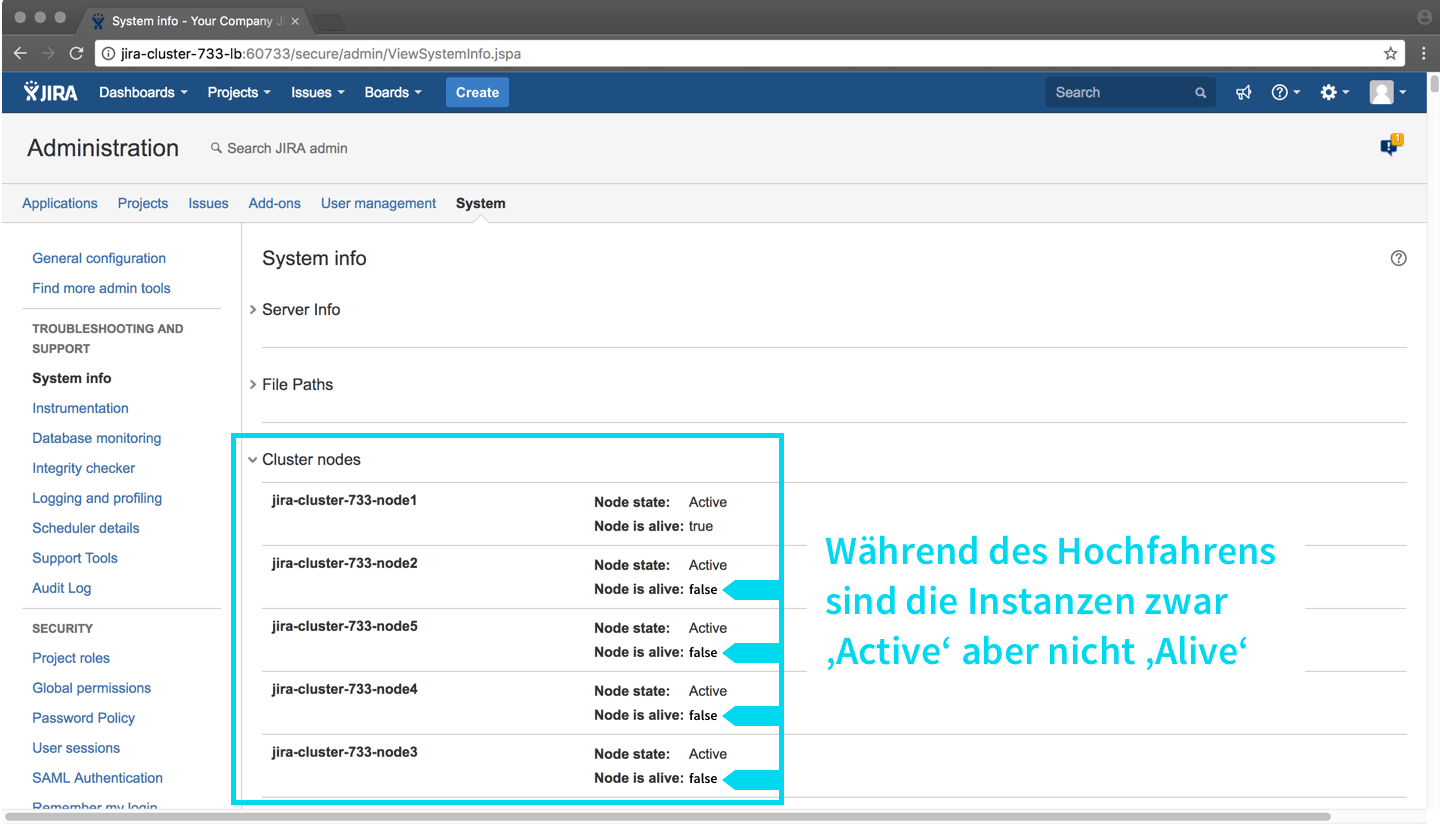
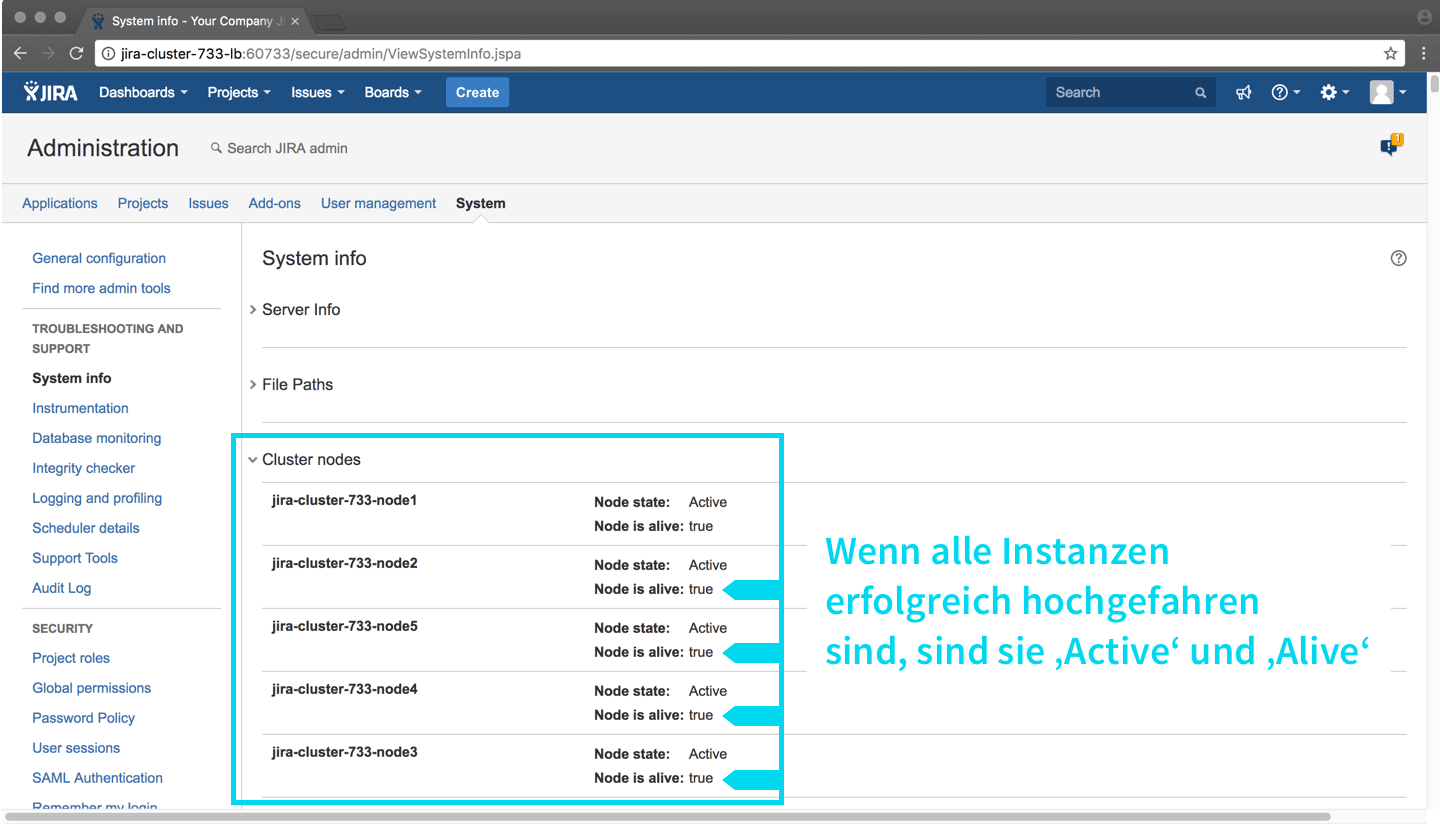
Nachdem alle Instanzen hochgefahren sind, sollten die Cluster Nodes alle als ‘Node is alive: true’ erscheinen.
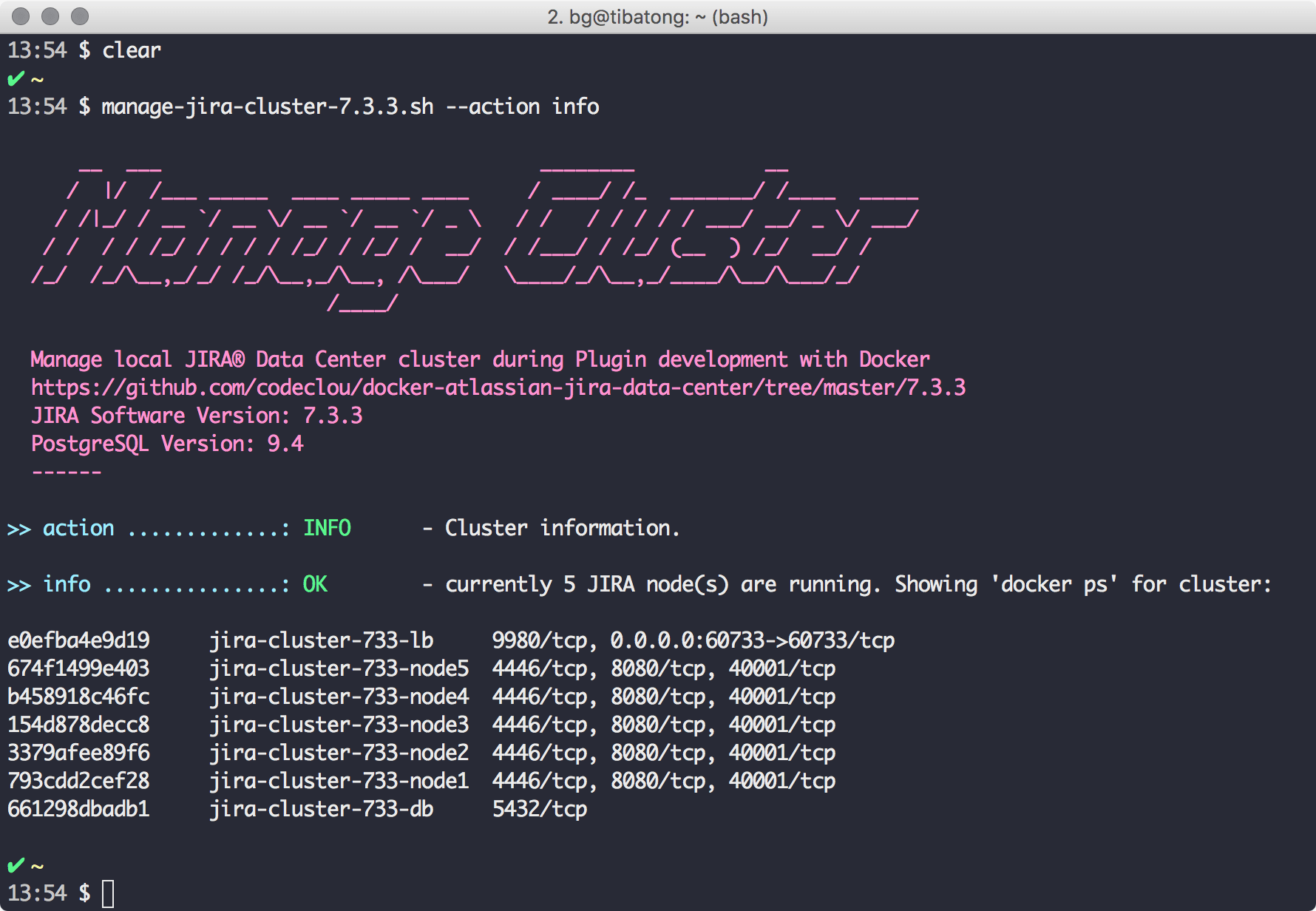
Wenn wir details über unser Cluster erfahren möchten, können wir das mit:
shell:manage-jira-cluster-7.3.3.sh --action info
Haben wir nun unser Plugin ausgiebig getestet, können wir das gesamte Cluster herunterfahren mit:
shell:manage-jira-cluster-7.3.3.sh --action destroy
FAZIT
So sehr habe ich mich noch nie über Docker gefreut wie in diesem Use Case. Genauso soll es ein. ‘Ich brauche jetzt ein JIRA Data Center!’. Ein Terminal-Kommando später läuft es. Natürlich ist diese Lösung nicht für den Produktivbetrieb gedacht, sondern nur als Wegwerf-Testumgebung während der Plugin Entwicklung. Dafür ist es wirklich ideal und spart mir sehr viel Zeit.
Wollen auch Sie von unserer Erfahrung mit Docker oder der Atlassian Tool Suite profitieren, dann schreiben Sie uns einfach unverbindlich über das unten stehende Kontaktformular an.