Do you want to learn how to apply high-performance distributed computing to real-world machine learning problems? Then this article on how we used Apache Spark to participate in an exciting Kaggle competition might be of interest.
The Lab
At comSysto we regularly engage in labs, where we assess emerging technologies and share our experiences afterwards. While planning our next lab, kaggle.com came out with an interesting data science challenge:
AXA has provided a dataset of over 50,000 anonymized driver trips. The intent of this competition is to develop an algorithmic signature of driving type. Does a driver drive long trips? Short trips? Highway trips? Back roads? Do they accelerate hard from stops? Do they take turns at high speed? The answers to these questions combine to form an aggregate profile that potentially makes each driver unique.1
We signed up for the competition to take our chances and to get more hands on experience with Spark. For more information on how Kaggle works check out their data science competitions.
This first post describes our approach to explore the data set, the feature extraction process we used and how we identified drivers given the features. We were mostly using APIs and Libraries provided by Spark. Spark is a “fast and general computation engine for large scale data processing” that provides APIs for Python, Scala, Java and most recently R, as well as an interactive REPL (spark-shell). What makes Spark attractive is the proposition of a “unified stack” that covers multiple processing models on local machine or a cluster: Batch processing, streaming data, machine learning, graph processing, SQL queries and interactive ad-hoc analysis.
For computations on the entire data set we used a comSysto cluster with 3 nodes at 8 cores (i7) and 16GB RAM each, providing us with 24 cores and 48GB RAM in total. The cluster is running the MapR Hadoop distribution with MapR provided Spark libraries. The main advantage of this setup is a high-performance file system (mapr-fs) which also offers regular NFS access. For more details on the technical insights and challenges stay tuned for the second part of this post.
Telematic Data
Let’s look at the data provided for the competition. We first expected the data to contain different features regarding drivers and their trips but the raw data only contained pairs of anonymized coordinates (x, y) of a trip: e.g. (1.3, 4.4), (2.1, 4.8), (2.9, 5.2), … The trips were re-centered to the same origin (0, 0) and randomly rotated around the origin (see Figure 1).

Figure 1: Anonymized driver data from Kaggle’s Driver Telematic competition1
At this point our enthusiasm got a little setback: How should we identify a driver simply by looking at anonymized trip coordinates?
Defining a Telelematic Fingerprint
It seemed that if we wanted useful and significant machine learning data, we would have to derive it ourselves using the provided raw data. Our first approach was to establish a “telematic fingerprint” for each driver. This fingerprint was composed of a list of features that we found meaningful and distinguishing. In order to get the driver’s fingerprint we used the following features:
Distance: The summation of all the euclidean distances between every two consecutive coordinates.
Absolute Distance: The euclidean distance between the first and last point.
Trip’s total time stopped: The total time that the driver has stopped.
Trip’s total time: The total number of entries for a certain trip (if we assume that every trip’s records are recorded every second, the number of entries in a trip would equal the duration of that trip in seconds)
Speed: For calculating the speed at a certain point, we calculated the euclidean distance between one coordinate and the previous one. Assuming that the coordinates units were meters and that the entries are distributed with a frequency of 1 second. This result would be given in m/s. But this is totally irrelevant since we are not doing any semantic analysis on it and we only compare it with other drivers/trips. For the speed we stored the percentiles 10, 25, 50, 80, 98. We did the same also for acceleration, deceleration and centripetal acceleration.
Acceleration: We set the acceleration to the difference between the speed at one coordinate and the speed at the previous one (when we are increasing speed).
Deceleration: We set the deceleration to the difference between the speed at one coordinate and the speed at the previous one (when we are decreasing speed).
Centripetal acceleration: We used the formulae:
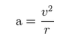
where v is the speed and r is the radius of the circle that the turning curve path would form. We already have the speed at every point so the only thing that is missing is the radius. For calculating the radius we take the current, previous and subsequent points (coordinate). This feature is an indicator of “aggressiveness” in driving style: high average of centripetal acceleration indicates turning at higher speeds.
From all derived features we computed a driver profile (“telematic fingerprint”) over all trips of that driver. From experience we know that the average speed varies between driving in the city compared to driving on the highway. Therefore the average speed over all trips for a driver is maybe not revealing too much. For better results we would need to map trip features such as average speed or maximum speed to different trip types like inner city trips, long distance highway trips, rural road trips, etc.
Data Statistics: Around 2700 drivers with 200 trips each, resulting in about 540,000 trips. All trips together contain 360 million X/Y coordinates, which means – as they are tracked per second – we have 100,000 hours of trip data.
Machine Learning
After the inital data preparation and feature extraction we could turn towards selecting and testing machine learning models for driver prediction.
Clustering
The first task was to categorize the trips: we decided to use an automated clustering algorithm (k-means) to build categories which should reflect the different trip types. The categories were derived from all trips of all drivers, which means they are not specific to a certain driver. A first look at the extracted features and computed categories revealed that some of the categories are indeed dependent on the trip length, which is an indicator for the trip type. From the cross validation results we decided to use 8 categories for our final computations. The computed cluster IDs were added to the features of every trip and used for further analysis.
Prediction
For the driver prediction we used a Random Forest algorithm to train a model for each driver, which can predict the probability of a given trip (identified by its features) belonging to a specific driver. The first task was to build a training set. This was done by taking all (around 200) trips of a driver and label them with “1” (match) and then randomly choosing (also about 200) trips of other drivers and label them with “0” (no match). This training set is then fed into the Random Forest training algorithm which results in a Random Forest model for each driver. Afterwards the model was used for cross validation (i.e. evaluating the error rate on an unseen test data set) and to compute the submission for the Kaggle competition. From the cross validation results we decided to use 10 trees and a maximum tree depth of 12 for the Random Forest model (having 23 features).
An interesting comparison between the different ensemble learning algorithms for prediction (Random Forest and Gradient-BoostedTrees (GBT) from Spark’s Machine Learning Library (MLib)) can be found on the Databricks Blog.
Pipeline
Our workflow is splitted into several self-contained steps implemented as small Java applications that can be directly submitted to Spark via the “spark-submit” command. We used Hadoop Sequence files and CSV files for input and output. The steps are as follows:

Figure 2: ML pipeline for predicting drivers
Converting the raw input files: We are faced with about 550,000 small CSV files each containing a single trip of one driver. Loading all the files for each run of our model can be a major performance issue, therefore we converted all input files into a single Hadoop Sequence file which is served from the mapr-fs file system.
Extracting the features and computing statistics: We load the trip data from the sequence file, compute all the features described above as well as statistics such as variance and mean of features using the Spark RDD transformation API and write the results to a CSV file.
Computing the clusters: We load the trip features and statistics and use the Spark MLlib API to compute the clusters that categorize the trips using k-means. The features CSV is enriched with the clusterID for each trip.
Random Forest Training: For the actual model training we load the features for each trip together with some configuration values for the model parameters (e.g. maxDepth, crossValidation) and start a Random Forest model training for each driver with labeled training data and optional testdata for crossvalidation analysis. We serialize each Random Forest model to disk using Java serialization. In its current version Spark provides native saving and loading of model result instances, as well as configuring alternative serialization strategies.
For the actual Kaggle submission we simply load the serialized models and predict the likelihood of each trip belonging to that driver and save the result it in the required CSV format.
Results and Conclusions
This blog post describes our approach and methodology to solve the Kaggle Driver Competition using Apache Spark. Our prediction model based on Random Forest decision trees was able to predict the driver with an accuracy of around 74 percent which placed us at position 670 at the Kaggle leaderboard at the time of submission. Not bad for 2 days of work, however there are many possible improvements we identified during the lab.
To learn more about the implementation details, technical challenges and lessons learned regarding Spark stay tuned for the second part of this post.
You want to shape a fundamental change in dealing with data in Germany? Then join our Big Data Community Alliance!
Sources:1. https://www.kaggle.com/c/axa-driver-telematics-analysis
