Today we would like to introduce you to the new MongoDB Full Text Search and compare its capabilities and performance with simple regular expressions, which are currently state of the art for searching in MongoDB. We will provide code snippets explaining how to use both features in a Java application as well as an empirical performance evaluation.
What is MongoDB Full Text Search?
MongoDB Full Text Search is a new feature in MongoDB 2.4. However, up to now it is in beta state and not recommended to use in production systems.
Why not continue to use regular expressions?
Basically, there are two major reasons. First, regular expressions have their natural limitations because they lack any stemming functionality and cannot handle convenient search queries such as “action -superhero” in a trivial way. Second, they cannot use traditional indexes which makes queries in large datasets really slow.
Nevertheless, searching via regular expressions is really easy to implement using Spring Data as demonstrated by the following code snippet:
github:7bf5b7002f2a491d13bb
How to use the MongoDB Full Text Search?
Unfortunately, this is a little harder as Spring Data does not yet support the feature. For implementing our own solution, we have to understand how a full text search can be executed in the Mongo shell:
github:b7b4a8487c0291176309
The command returns a single json document with all objects that match the query and some statistics on the search that has just been executed. Translating this into Java code that extracts the IDs of all matches works as follows.
github;ff88df2502544488f16f
Note that there is no indicator for the field to search in! As MongoDB supports only one text index per collection this information is implicitly specified after defining it in the shell
github:a9234cf1ed987cbbb686
or from the Java application
github:ab8302b2ca76b85a515e
In order to provide search results with pagination and custom sorting for the application’s UI layer, we need another standard Spring Data query that does exactly that.
github:7ef9e7f1ffb130aee5e9
This two-step approach ensures we can use all the functionality of a regular MongoDB query (sorting, pagination, additional criteria, …) while taking advantage of MongoDB’s current full text search implementation.
What are limitations of the MongoDB Full Text Search?
The full text search does not work properly for really large datasets as all matches are returned as a single document and the command does not support a “skip” parameter to retrieve results page-by-page. Despite of projecting to nothing but the “_id” field a huge set of matches will not be returned in its entirety if the result exceeds Mongo’s 16MB per document limit.
How does the MongoDB Full Text Search perform compared to regular expressions?
To get a feeling how fast the MongoDB Full Text Search works in different cases, we built a small demo application which imports data from The Movie Database and displays them in a list. Entering a search term in the search field, one can decide to run it with or without the MongoDB Full Text Search. The time results in ms are printed to the console.
For our example we imported 100,000 movies and searched for three different words, always retrieving the first page with up to 15 entries but counting the number of all matches (for calculating the number of required pages):
– “movie” which delivers 3,533 matches with the full text search and 3,317 with regular expressions (the number differs due to the full text search’s stemming functionality)
– “newspaper” which delivers 318 matches with the full text search and 320 with regular expressions
– “Mayzie” which delivers 2 matches in both cases
The following bar chart illustrates the corresponding performances for counting the results and retrieving them:
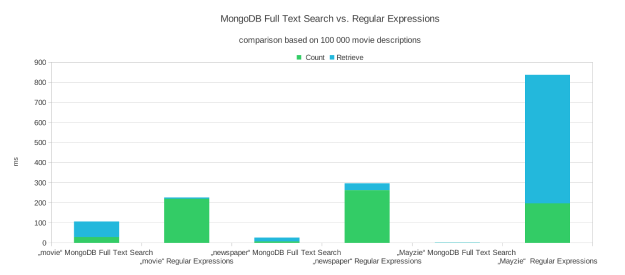
The chart indicates two major trends. The regular expression search takes longer for queries with just a few results while the full text search gets faster and is clearly superior in those cases. Why is that?
Let’s explain the results for searching with regular expressions first. The time for counting the number of matches among the 100,000 entries is pretty consistent at about 200ms. Obviously, this is the time required to scan the entire collection document by document as no index can be used here. On the other hand, the time to retrieve one page goes up tremendously for a smaller number of results. This is due to the fact that MongoDB uses an index for iterating over all documents in the correct sorting order and can stop immediately as soon as 15 entries for the first page have been found. For a query with about 3,500 matches in 100,000 documents (“movie”) the expected value of documents to be scanned is only 15/0.035=428.6 while the entire collection needs to be checked for a very rare search term such as “Mayzie”.
Explaining the full text search performance is quite straightforward. In this case, MongoDB can use an index and hence the query is always efficient. It only requires slightly more time for an increasing number of matches. An important issue to understand here is that the time to retrieve the first page includes executing the full text search, extracting all result IDs in the application and running another standard query as explained above. The time required for the extraction step increases linearly with the number of matches which is the major reason for the rise of retrieval time for bigger result sets even though only 15 entries are returned.
What do you need to run this demo yourself?
Our demo application uses Spring, Spring Data, Apache Wicket, Gradle and MongoDB.
To get started download the code from https://github.com/comsysto/mongo-full-text-search-movie-showcase.
To start your MongoDB with full text search enabled, shutdown your mongod if it’s currently running and then command:
github:a35fc325af751a757a70
Alternatively, you can add this line to your mongodb.conf file for permanently enabling the feature (not recommended in a production environment):
github:5d7f778be3f6e27dcd80
If you haven’t installed gradle, follow this manual. Then command
github:230eea0d87a2fc7a6cdb
To start the application command
github:9d636c6b0281d591ec3e
What may help if you have problems?
If the full text search is not properly configured you will always obtain an empty result list no matter which term you were searching for. Additionally, the message “### MongoDB Full Text Search does not work properly – cannot retrieve any results.” will be printed to the console.
This behavior can have multiple causes:
- You haven’t started your mongod server with the textSearchEnabled=true option as described above.
- You have specified more than one text index for the collection which cannot be handled by MongoDB. You can look this up by calling the following in a mongo shell:
github:94b0494540fa5ceb98e7
How can this demo be extended?
Starting with this little demo you can extend it as you wish to. If you are using The Movie Database, please create your own account here and use your own API key.
Any questions?
If you have any feedback, please write to Christan.Kroemer@comsysto.com!