Scaling in general describes methods of adding more resources to a given system. We can distinguish between two approaches:
Scale vertically (up)
“To scale vertically (or scale up) means to add resources to a single node in a system, typically involving the addition of CPUs or memory to a single computer. ”
Scale horizontally (out)
“To scale horizontally (or scale out) means to add more nodes to a system, such as adding a new computer to a distributed software application. An example might be scaling out from one Web server system to three.”
Using MongoDB you have two basic ways of scaling depending on what aspect of your system you need to improve. You can either focus on read operatioins or on write operations.
10gen tells us the following about MongoDB’s scalability options:
“With built-in support for horizontal scalability, MongoDB allows users to build and grow their applications more rapidly. With auto-sharding, you can easily distribute data across many nodes. Replica sets enable high availability, with automatic failover and recovery of database nodes within or across data centers.”
Sound’s great, doesn’t it? So let’s get started and do a batch import of ~24.000.000 records into an auto-sharded MongoDB cluster consisting of six nodes:
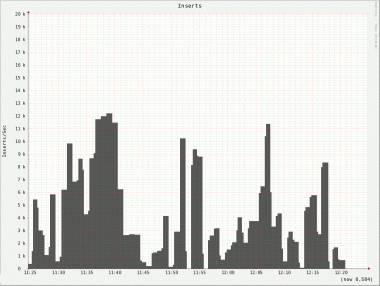
Well, doesn’t look too good, does it? The very rocky graph suggests a very uneven write performance. It get’s even worse if you look at the individual nodes:
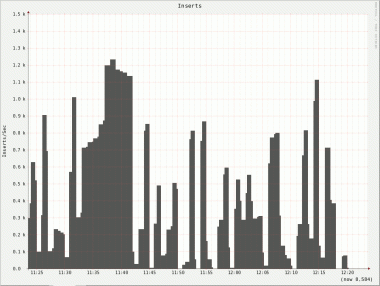
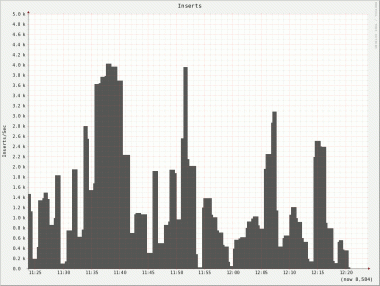
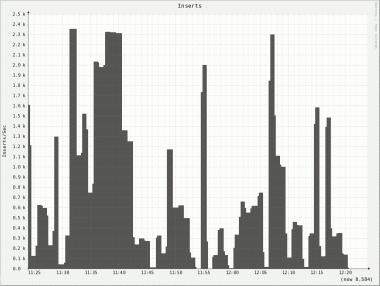
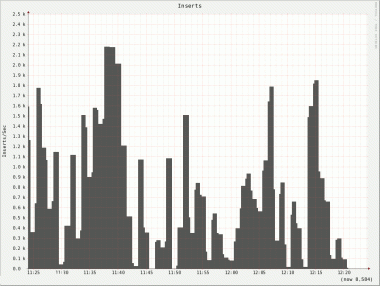
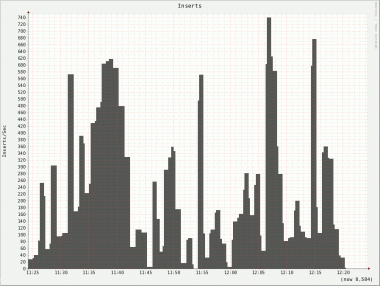
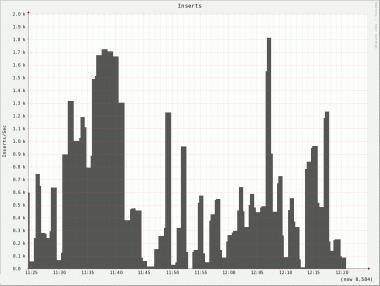
Not only do we see the same uneven behavior on all nodes but there is also a huge difference on inserts/s between nodes. Node 2 has a peek of roughly 4000 inserts/s whereas node 5 only has a peek of 740 inserts/s!
So what’s happening? At first everything looks fine during the import using mongoimport and we get nice throughput to our cluster but over time insert rates slow down significantly. Actually a quick look into mongostat reveals that some nodes don’t input any data at all for several seconds!
To understand what’s going on we have to take a look at how sharding in MongoDB works. On a high level there are three basic components:
- Mongo Sharding Router (mongos) responsible for transparent query routing from the application layer
- Mongo Config Server responsible for holding metadata about which ranges of data reside on which node
- Mongo Shard Node common mongod process that holds actual data
So in order to store data into such a cluster you have to do metadata queries to check on which node the current record has to be written to.
So far so good. We now understand that there is an overhead at each write operation to decide the target node to write to but that shouldn’t produce such a massive performance hit!
But in the harsh reality it does! As mentioned before MongoDB does range-base partitioning of your data. This means that you have to tell MongoDB which part of your data is to be used to partition on. This is the so-called “shard key”. There are also lots of things that can go wrong when you make a bad decision on what your shard key is. But for the sake of brevity let’s say that we picked a shard key that’s considered well suited for our kind of data.
What MongoDB now does is it internally puts your data in so-called “chunks”. These are like data buckets of a fixed size. So each chunk contains a certain range of data and only a certain amount of data (default: 64MB). When we import data into the database these chunks fill up and when they reach their size limit they get split up by MongoDB. When that’s the case two things happen:
- New metadata information has to be written to the config servers
- The balancer has to decide if a chunk has to be moved to another node
Now the second point is the interesting one! Since we haven’t told MongoDB anything about the range of our shard key or how it is distributed MongoDB can’t do anything but take an estimated best guess and try to distribute data evenly among shards. It does that by a strategy of keeping the number of chunks that reside on a node at any given time roughly the same on across all nodes. In Mongo 2.2 new migration thresholds were introduced to minimize the impact of balancing to the cluster. Also since Mongo doesn’t know anything about the range and distribution of our shard key it may very well happen that it creates “hot spots” so that a large part of data is written into one shard and thus on only one node.
So now that we know what’s going on what can we do to speed things up?
Pre-split your data
This requires some knowledge about the data you’re going to import. So instead of leaving MongoDB the choice of which chunks to create you have to do it yourself. Depending on the kind of shard key you have you can either use a script to generate the necessary commands (look here for a good example of that) or use an approach like in the MongoDB documentation. Anyway you will end up telling MongoDB where to split your chunks like so:
db.runCommand( { split : "mydb.mycollection" , middle : { shardkey : value } } );
After you have done this you can also tell MongoDB which of those chunks should reside on which node. Again this depends on your use case and how data is read by your application. So keep things like data locality in mind. In the example above I’ve created a sha1 hash of a date and two ID strings. I then used the first two letters of each hash as a shard key. This still leaves some room for optimization but your mileage may vary.
Increase chunk size
The documentation has the following to say on chunk sizes:
- Small chunks lead to a more even distribution of data at the expense of more frequent migrations, which creates expense at the query routing (mongos) layer.
- Large chunks lead to fewer migrations, which is more efficient both from the networking perspective and in terms internal overhead at the query routing layer. Large chunks produce these efficiencies at the expense of a potentially more uneven distribution of data.
So in order to get data into MongoDB as quickly as possible I increased the chunk size to 1GB. Knowing my data I know that this will be sufficient for quite a while. Again you have to decide for yourself if that value makes sense.
Turn off the balancer
As we haved told MongoDB which chunks should live on what node and we don’t suspect any new chunks to be created we can safely turn off the balancer by issuing the following commands:
use config
db.settings.update( { _id: "balancer" }, { $set : { stopped: true } } , true );
Pick a good shard key
A very essential point for a good distribution among nodes. Please read this to get some hints on what to look for. Also in MongoDB 2.4 there should be the option to let MongoDB use a hashed shard key for you.
After doing all this and repeat the import the situation is now like this:
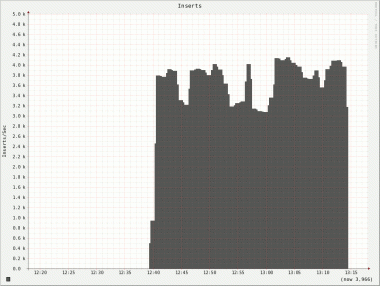
This is the input rate on one cluster node now. There are still some dips because the data does not come in that evenly distributed. But overall it’s a huge improvement from 4608 inserts/s into the whole cluster where as now imports are limited by the network interface of the single mongos that’s feeding the data in!
Conclusion
So to sum things up MongoDB can deliver really outstanding performance for batch imports. But as everyone knows: “There ain’t no such thing as a free lunch” and so you have to get your hands dirty and get down to the nitty-gritty details of sharding and most importantly your data model and access patterns.