EINLEITUNG
In meinem vorherigen Blogpost habe ich über Docker und den möglichen Einsatz von Docker-Containern als Produktivsystem geschrieben.
Diese BlogPost-Serie wird ein ‘Behind the Scenes Artikel zur Infrastrukturmigration’ unseres internen Lebenslauf-Management Projekts genannt SeeVee. Wir wollen für das Projekt SeeVee die Infrastruktur von Dockerized-AWS-Instanzen hin zu Boxfuse-managed-AWS-Instanzen migrieren, damit die Komplexität des Systems enorm reduzieren, gleichzeitig die Wartbarkeit sowie Robustheit des Gesamtsystems erhöhen. Die frei werdenden Resourcen aus dem Infrastruktur-Management können im Projekt vollständig auf die Software-Entwicklung verwendet werden. Boxfuse eignet sich besonders für entwicklungsfokussierte Projekte mit geringem bis keinem DevOps Anteil.
Uns ist auch klar, dass es mehrere Wege nach Rom gibt und man mit Amazon EC2 Container Service zusammen mit Amazon EC2 Container Registry und Amazon AWS Elastic Beanstalk ähnliches auch mit Docker erreichen könnte. Da man aber in all diesen Lösungen höheren Administrationsaufwand hat, haben wir uns für die aufwandsfreie Boxfuse Lösung entschieden.
Es soll unter anderem gezeigt werden, wie man sehr einfach mit Boxfuse eine modulare Microservice Architektur mit mehreren Self Contained Services (SCS) aufsetzen kann.
Ziel von Teil I der BlogPost-Serie ist die Analyse, das Aufstellen eines Migrationsplans und ein Proof of Concept der Infrastruktur-Anforderungen.
DER GEIST DER VERGANGENHEIT - IST-INFRASTRUKTUR
Die IST-Infrastruktur der SeeVee Anwendung gestaltet sich wie folgt.

Basis bildet die PostgreSQL SeeVee-Datenbank welche als AWS t2.small Instanz aufgesetzt ist und die Produktiv- und Stagingdatenbank bereitstellt. Das SeeVee-Backend ist eine SpringBoot Anwendung mit Spring Data JPA Rest API. Die Datenbankmigration ist mit Flyway implementiert. Die Laufzeitumgebung bildet ein Docker-Container welcher die Java JRE sowie Imagemagick und PhantomJS bereitstellt. Auf AWS sind zwei t2.micro Instanzen für Produktiv- und Staging-Umgebung deployed. Im SeeVee-Frontend kommt React zum Einsatz und bildet mit einigen anderen Frameworks eine ‘Single Page Application’. Gehostet wird das Frontend auf GitHub-Pages mit einem vorgeschalteten TLS-Proxy. Der Globale-TLS-Proxy enthält ein Wildcard-Zertifikat für ‘*.comsysto.com’ und ‘ProxyPass’-Direktiven auf verschiedene Services, darunter Direktiven für Frontend und Backend. Implementiert ist der Proxy als ein Ansible-gesteuerter nginx auf AWS. Die Globale-Docker-Registry läuft auch auf AWS und dient zum Deployment (Zwischenspeicher) der Docker-Images. Die Registry bleibt auch nach der Migration bestehen, da wir sie auch für andere Projekte nutzen, deshalb zeichne ich sie auch nicht ins Diagramm ein und wir ignorieren sie einfach im Folgenden.
WARUM WEG VON DOCKER UND HIN ZU BOXFUSE?
Boxfuse ist ein Dienst, der es ermöglicht minimale unveränderbare (immutable) Images zu bauen und von der Entwicklungs- bis zur Produktivumgebung zu nutzen. Man befolgt das Paradigma ‘build once deploy everywhere’. Weiterführende Informartionen zu immutable-infrastructure erfahren Sie hier. Die Unterschiede sowie Vor-/Nachteile gegenüber Docker wurden bereits hier schön illustriert.
Die Vorteile die Boxfuse uns im speziellen bietet manifestieren sich besonders in den vorgegeben Prozessen wie beispielsweise den dev, test und prod Environments, welche es einem ermöglichen auf dem lokalen Rechner die Anwendung schon 1:1 so hochzufahren und zu testen, wie sie später auch bei AWS deployed wird. Besonders die auto-scaling Funktionalität von Boxfuse erleichert einem die Betreuung von Last-Intensiven Produktivanwendungen enorm. Kurz gesagt: Man hat den vollen Komfort eines Software-As-A-Service Dienstes (SAAS) mit der vollen Flexibilität eines Infrastructure-As-A-Service Dienstes (IAAS) wie AWS.
Wir betreiben das SeeVee-Backend jetzt schon seit einem Jahr mit Docker und es ist schon einige male passiert, dass sich entweder die Docker-Registry aufgehängt hat oder der Docker-Host-Prozess auf dem eigentlichen System abgestürzt ist. Darüber hinaus ist SeeVee auch ein internes Schulungsprojekt für neue Junior-Mitarbeiter welche von der Komplexität der Docker-Deploy-Chain oft überfordert sind.
Generell wollen wir folgende Ziele erreichen:
- Abschaffen der Docker-Registry für SeeVee
- Komplizierte Deploy-Chain von Jenkins über Docker-Registry nach AWS Instanz abschaffen
- Immutable Infrastructure von Entwicklung bis Produktivumgebung durchgehend nutzen
- Klarheit und Einfachheit durch gut dokumentierte Prozesse etablieren
- Gerüstet sein für zukünftiges Rollout des Projekts mit erhöter Lasterwartung
- Externe Abhängigkeiten reduzieren und SCS (Self Contained Services) schaffen
WARUM NICHT GLEICH SAAS WIE HEROKU NUTZEN?
Heroku ‘verbirgt’ die Infrastruktur vor einem, während Boxfuse einen existierenden AWS Account nutzt und man die Infrastruktur auch ohne Boxfuse weiterbetreiben bzw. alles speziell anpassen kann. Man kann aufgrund der klaren Struktur auch manuell erstellte AWS Instanzen zusammen mit Boxfuse-managed Instanzen betreiben.

Besonders das Thema Datenschutz ist uns wichtig. Hierzu haben wir mit AWS für den Standort Frankfurt bereits eine Vereinbarung zur Datenverarbeitung abgeschlossen und werden dies auch mit Boxfuse noch tun. Somit lassen sich auch datenschutzkonform personenbezogene Daten auf der Infrastruktur verarbeiten.
Historisch gesehen war SeeVee zuerst eine monolithische Anwendung deployed auf Heroku mit einer server-seitigen View-Komponente. Das wurde im Zuge der Migration auf Docker aufgesplittet in Frontend und Backend welche über REST kommunizieren. Diese Teilung von Frontend und Backend wollen wir beibehalten.
WAS MACHT DAS SEEVEE-BACKEND?
Bevor wir jetzt munter mit der Migration beginnen, erkläre ich kurz die Komponenten von SeeVee.
Das SeeVee-Backend ist eine SpringBoot Anwendung, welche mittels Spring Data JPA auf eine PostgreSQL Datenbank zugreift. Die Daten aus der Datenbank werden dem SeeVee-Frontend via REST zur Verfügung gestellt. Einzige Besonderheit ist der oAuth Login via GitHub, welcher vom Backend vorgenommen wird. Dabei wird man zu GitHub redirected, authentifiziert und wird zurück zum Backend geleitet. Das Backend legt automatisch basierend auf den GitHub Organizations des Users diese als interne ‘Company’ Objekte in der Datenbank an. Auch der GitHub User wird mit seinem Fremdschlüssel in der Datenbank als ‘User’ Objekt abgelegt.
Hier ist unser Entity-Relationship Diagramm der SeeVee-Datenbank und haltet euch fest, es ist mit dem besten Design Werkzeug überhaupt erstellt - ASCII!!!
github:028432fead767861d0be69295ecedd57
Warum ASCII und nicht Zeichentools Visio/Gliffy/Draw.io nutzen? Der Grund dafür ist einfach: ‘The Lazy Developer’ - Je höher die Hürde ist, bspw. durch Benutzung eines Programms das erst installiert werden muss, so geringer ist die Chance, dass das ER-Digramm kontinuierlich gepflegt wird. ASCII direkt in der README.md als Teil der Code-Base ermöglicht die Pflege durch jeden Entwickler.
Ich fasse die Aufgaben des Backends nun stichpunktartig zusammen:
- Authentication und Authorization (GitHub oAuth + Spring Security)
- Speicherung von Firmendaten, Benutzerdaten, Benutzer-Portraits und Lebensläufen
- Zuschneiden (Cropping) von Portraits mittels Imagemagick
- Erstellen von PDF Versionen der Lebensläufe mittels PhantomJS ‘rasterize’
- Bereitstellen einer REST API zum Zugriff auf alle Daten
- Datenbankmigration via Flyway
WAS MACHT DAS SEEVEE-FRONTEND?
Kurz gesagt MAGIC. Nein Spaß bei Seite - das Frontend ist eine React Anwendung, welche eine React Code-Base auf ES6+Babel Basis besitzt. Redux, Redux-Form, React-Redux-Router und Redux-Saga werden zur Zustandssteuerung eingesetzt. Mittels der Browser-Bibliothek Fetch werden die Anfragen an die SeeVee-Backend REST API gestellt.
Das Besondere am Frontend ist der auf Json basierende Lebenslauf, dessen Schema nur dem Frontend bekannt ist. Das Backend speichert das JSON wie bei einer NoSQL Datenbank 1:1 ab. Warum dann nicht MongoDB nutzen statt PostgreSQL? Hätte man tun können, da SeeVee aber ein Schulungsprojekt ist, wollten wir den SpringBoot+JPA+PostgreSQL Stack verwenden, da dieser sehr oft in unseren Kundenprojekten verwendet wird.
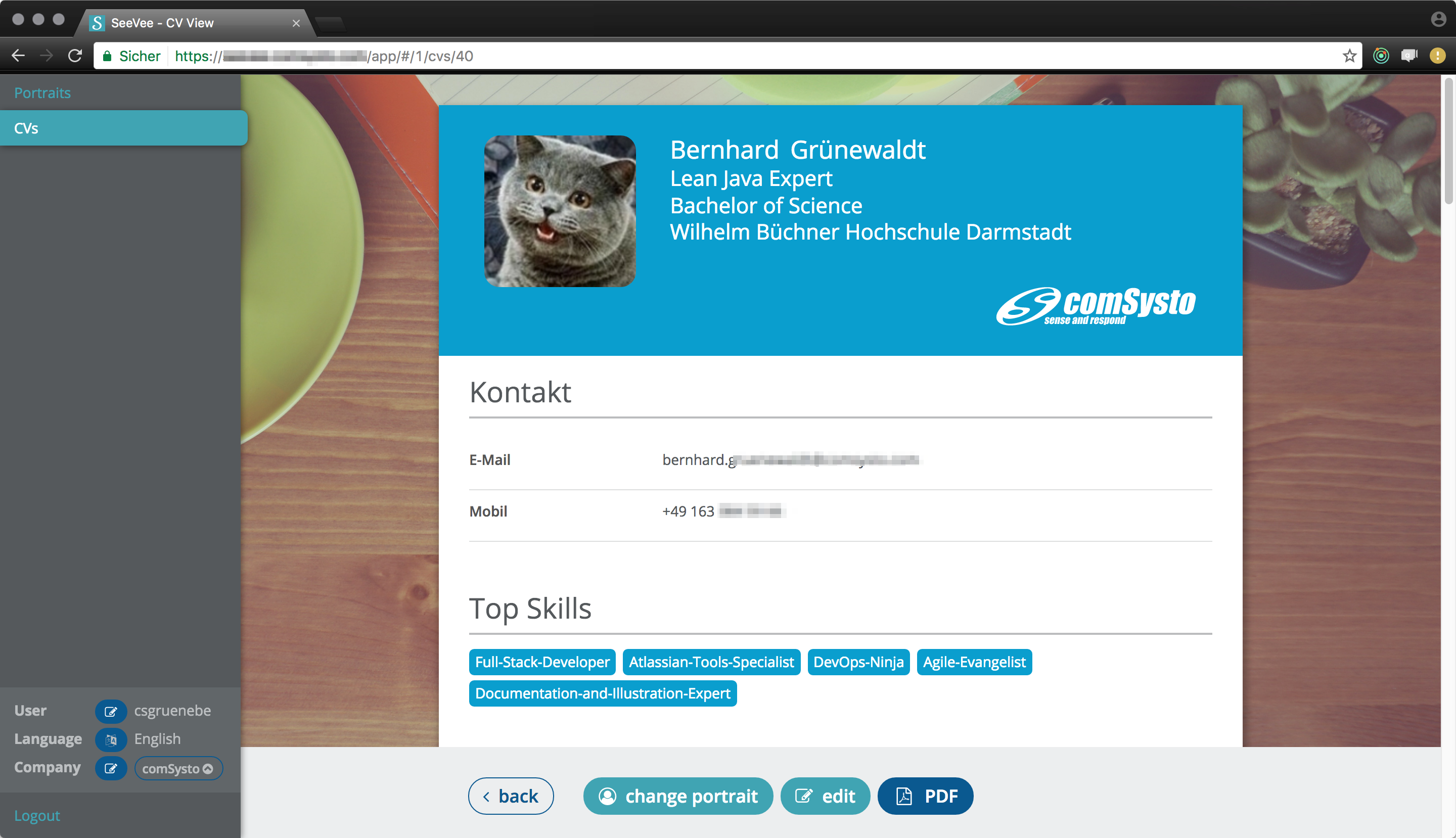
Die PDF Generierung des Lebenslaufes wird browser-seitig durch Konvertierung der CV-React-Component in static HTML vorbereitet. Anschließend wird das HTML-Snippet zusammen mit dem CSS-Code an das Backend gesendet, welches daraus ein PDF generiert. Somit ist man sehr flexibel und hält die Abhängigkeiten zwischen Frontend und Backend sehr gering. Die PDF Generierung ist dabei mit einer Redux-Saga gelöst, die asynchron arbeitet. Für die gesamte Code-Base wird mit ESLint ein Codestyle enforced.
Zusammenfassend gesagt sind die Aufgaben des Frontends:
- Bereitstellen der UI zur Interaktion mit dem Benutzer
- Bereitstellen von Formularen zur Eingabe des Lebenslaufs
- Preview des Lebenslaufes und PDF download
- Hochladen eines Portraits und Zuweisung zu einem Lebenslauf
- Globale Einstellung der CV Farben und Firmenlogo
INFRASTRUTKUR-ANFORDERUNGEN VON SEEVEE
Damit wir jetzt nicht einfach lustig ins blaue hinein migrieren, halten wir an dieser Stelle die Anforderungen von SeeVee an die Infrastruktur fest. Natürlich bedingt eine Auto-Scaled-Applikation ein stateless non-sticky Loadbalancing zwischen den Instanzen, was wiederum eine ganze Reihe von Dingen nach sich zieht, mit denen die Anwendungen umgehen müssen. Je früher und genauer wir all diese Anforderungen zusammenschreiben, umso weniger Überraschungen erleben wir während der Migration. Ich versehe jede Anforderung mit einer eindeutigen ID auf welche ich später Bezug nehmen werde.


Nach dem Erstellen der Infrastruktur-Anforderungen prüfe ich immer kurz die Dokumentation und erstelle ggf. kleine Proof-of-Concept-Projekte, um einzelene Anforderungen auf Erfüllbarkeit zu prüfen. So identfiziert man früh im Prozess Impediments. Ein Bereits jetzt ersichtliches Impediment ist (BAF-7), da das Backend aktuell auf ein Sticky-Session-Loadbalancing setzt. Wir müssen uns also während der Migration auch darum kümmern Technical Debt abzubauen. Anhand der Boxfuse Dokumentation und einiger kleiner PoCs kann ich alle anderen Anforderungen bereits als machbar abhaken.
MIGRATIONSPLAN
Boxfuse kann für uns die Applikations- und Datenbankinstanzen verwalten. Die Zielvorstellung ist daher sehr einfach. Wir müssen nur zwei “Apps” in Boxfuse erstellen und diese stellen für uns alles automatisch bereit:
- Datenbank-Instanz (RDS) mit automatischem Failover (Multi-AZ)
- Backend Applikations-Instanz mit Auto-Scaling (EC2)
- Frontend Applikations-Instanz mit Auto-Scaling (EC2)
- Sub-Domain unter *.boxfuse.io auf die wir CNAME *.seevee.io schalten
- Staging- (dev) und Produktivumgebung (prod)
- Deployment und Rollback bequem via Boxfuse-Vault (=Image Repository)
- SSL Zertifikat einbindbar auf Instanz (wir bestellen ein Wildcard Zertifikat)
Dargestellt als Bild sieht unsere Soll-Infrastruktur nun wie folgt aus.

Auch wenn das obige Diagramm kompliziert wirkt, so ist es doch mit einem Klick eingerichtet. Wir Erstellen eine Load Balanced und Auto Scaling Applikation für SeeVee-Backend und erhalten alles automatisch konfiguriert.
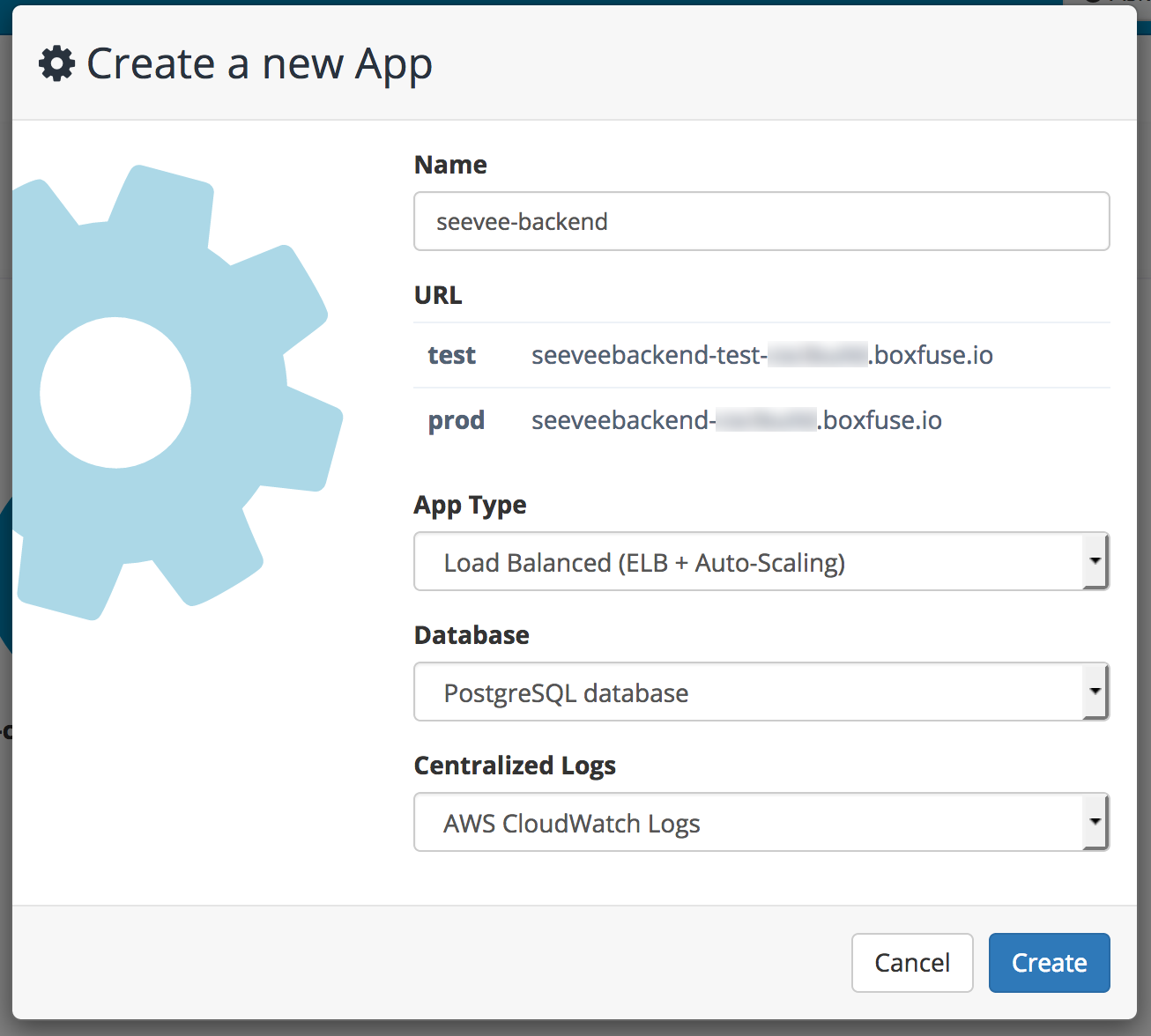
Analog Erstellen wir eine Load Balanced und Auto Scaling Applikation für SeeVee-Frontend jedoch ohne Datenbank.
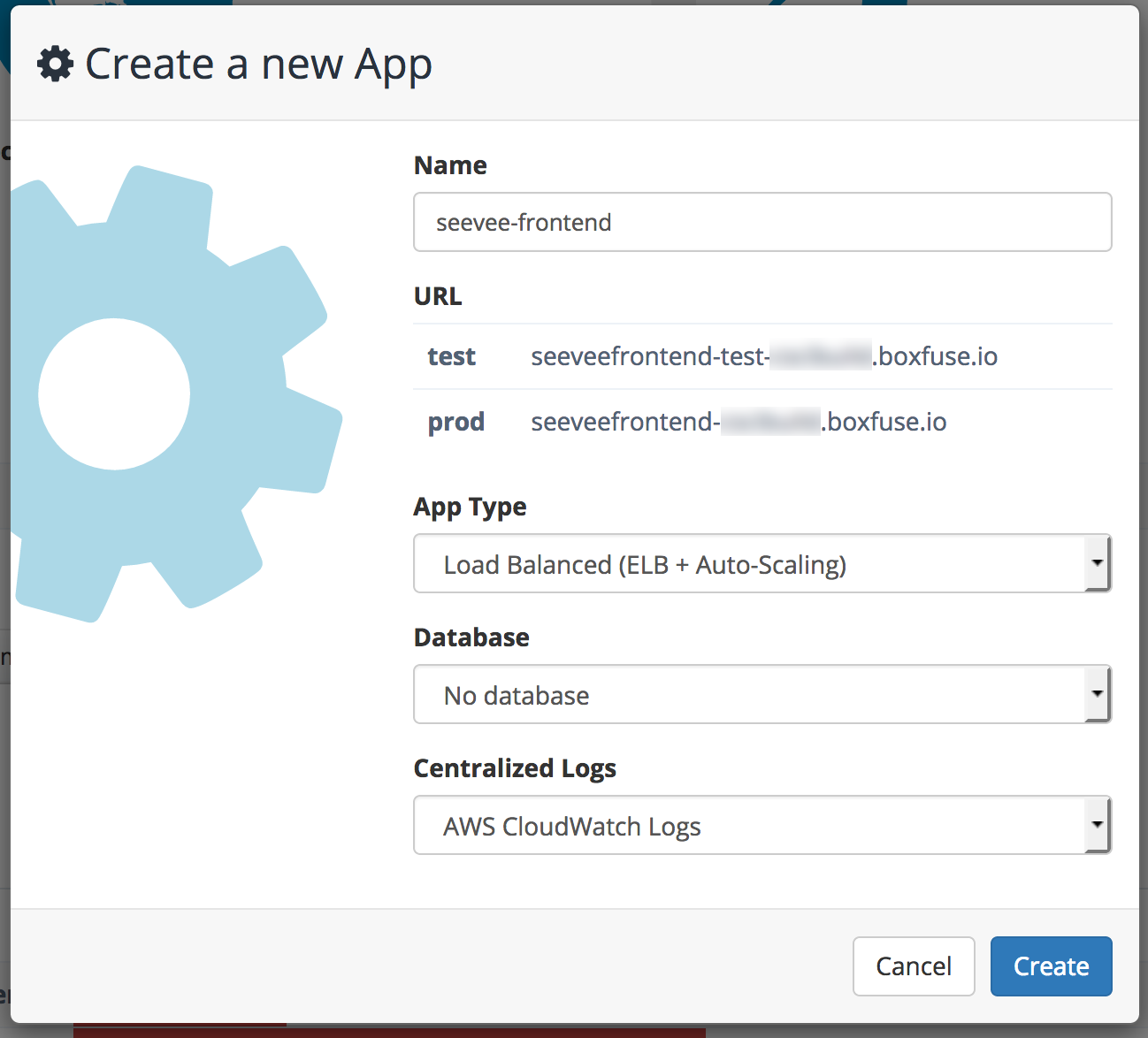
Nachdem wir beide Anwendungen angelegt haben sieht die Übersichtsseite von Boxfuse wie folgt aus.
Da wir nun den prinzipiellen Rahmen unserer neuen Infrastruktur kennen brauchen wir nun eine Detailplanung der Migration:
Backend
- Gradle-Build mit Boxfuse ‘verheiraten’. Dabei Oracle JDK 8 sowie Imagemagick und PhantomJS bundlen.
- In der SpringBoot Anwendung Environment Variablen (BAF-8) nutzen, sodass (1) mittels ‘BOXFUSE_ENV’ Environment erkannt wird (2) mittels ‘BOXFUSE_DATABASE_URL’ die Datenbankverbindung genutzt werden kann
- Da wir bereits Flyway nutzen, werden die Datenbank-Tabellen beim Hochfahren der SpringBoot Anwendung automatisch angelegt.
- Wildcard SSL Zertifikat auf Instanz einbinden (BAF-5).
- Deployment von SeeVee-Backend via Boxfuse und CURL-Test-Requests, um Erfolg zu testen.
Frontend
- SeeVee-Frontend NodeJS-Build mit Boxfuse ‘verheiraten’.
- NodeJS Express Server Anwendung erstellen und Wildcard SSL Zertifikat einbinden (FAF-4).
- Express Server soll einfach nur statischen Content ausliefern.
- Express Server soll die ‘/env.js’ mit der ‘BOXFUSE_ENV’ Environment-Variable generieren (FAF-6).
Abschließende Tätigkeiten
- GitHub oAuth App URLs anpassen bei GitHub.com und in den SeeVee-Settings.
- End-To-End Tests auf Dev und Prod laufen lassen sowie manuelle Smoke-Tests ausführen.
- Datenbankmigration Produktivumgebung: Dump von PostgreSQL der alten Produktiv-Datenbank machen und in neuer Produktiv-Datenbank einspielen.
- Alte AWS Instanzen terminaten.
ITERATION 1: SEEVEE-BACKEND LOKAL MIT SPRINGBOOT UND POSTGRESQL-DB STARTEN
Wir gehen iterativ vor und passen in der ersten Iteration unseren existierenden Gradle-Build an, sodass er nun anstatt nur ein ‘seevee.jar’ zu bauen zusätzlich mit dem Boxfuse Gradle Plugin eine unveränderbare Infrastruktur auf der lokalen Workstation bereitstellt. Wir wollen, dass Boxfuse dabei die im ‘seevee.jar’ enthaltene SpringBoot Anwendung und eine zugehörige PostgreSQL Datenbank startet.
Im Folgenden beschreibe ich die nötigen Anpassungen an unserem Build, sodass wir mit Boxfuse lokal das SeeVee-Backend starten können.
Zuerst passen wir die ‘build.gradle’ an und fügen das Boxfuse Gradle Plugin ein.
github:0c0defe6e54f3c07f51877f161156e0b
Als nächstes müssen wir die Boxfuse-Credentials in die ‘.bashrc’ eintragen. Wir könnten diese auch in die ‘build.gradle’ schreiben, aber unsere Security Policy verbietet das Eintragen von Zugangsdaten in Source-Code. Anschließend müssen wir die Datei mit ‘source ~/.bashrc’ neu einlesen.
github:1ceb041f1e6239e66b79aa4324b4c720
Wir haben schon in der Einführung zu Boxfuse die Anwendung ‘seevee-backend’ über die Boxfuse-Web-GUI erstellt, und überspringen daher den ‘create’ Application-Schritt. Jedoch müssen wir stattdessen die Einstellungen der Applikation in die ‘build.gradle’ eintragen, damit Boxfuse den Zusammenhang zwischen der ‘seevee-backend’ Applikation und unserem Projekt herstellen kann. Diese Einstellungen teilen dem Boxfuse Client bspw. auch mit, dass wir lokal gerne eine PostgreSQL Datenbank brauchen.
github:eb206d07255b88d9235fb4c34fc9b178
Würden wir die Autoconfiguration der Datenbank in SpringBoot nutzen, würden sich die Datenbankeinstellungen automatisch über von Boxfuse bereitgestellte Environment-Variablen vornehmen. Wir mappen diese Variablen aber lieber manuell auf unsere Spring-Datasource Variablen in unserer ‘application.yml’. Diese benennen wir vorher aber noch nach ‘application-boxfuse.yml’ um, da Boxfuse das so erwartet.
github:df61970ba2cf4752af5de3f08c2046bb
Die Konfiguration ist damit abgeschlossen und wir starten die Anwendung. Wir haben vorher natürlich VirtualBox installiert welches von Boxfuse genutzt wird, um lokal die unveränderbare Infrastruktur hochzufahren.
shell:./gradlew boxfuseRun -Dboxfuse.env=dev
Mit diesem Befehl wird die Anwendung gebaut und hochgefahren. Dank meiner extrem langsamen Internet-Verbindung tat sich lange nichts und ich bekam auch keine Ausgabe, was vor sich geht, daher beendete ich den Befehl und startete ihn nochmal mit debug neu.
shell:./gradlew --debug boxfuseRun -Dboxfuse.env=dev
Jetzt konnte ich sehen, dass über AWS-S3 das boxfuse-dev-hdd-2016.02.09.vmdk.xz Basis-Image für die virtuellen Maschinen heruntergeladen wird. Ein guter Zeitpunkt für mich Kaffeetrinken zu gehen. Nachdem es dann hochgefahren war lässt sich der Befehl ‘boxfuseInfo’ ausführen, um Details zur laufenden Anwendung anzuzeigen.
shell:./gradlew boxfuseInfo
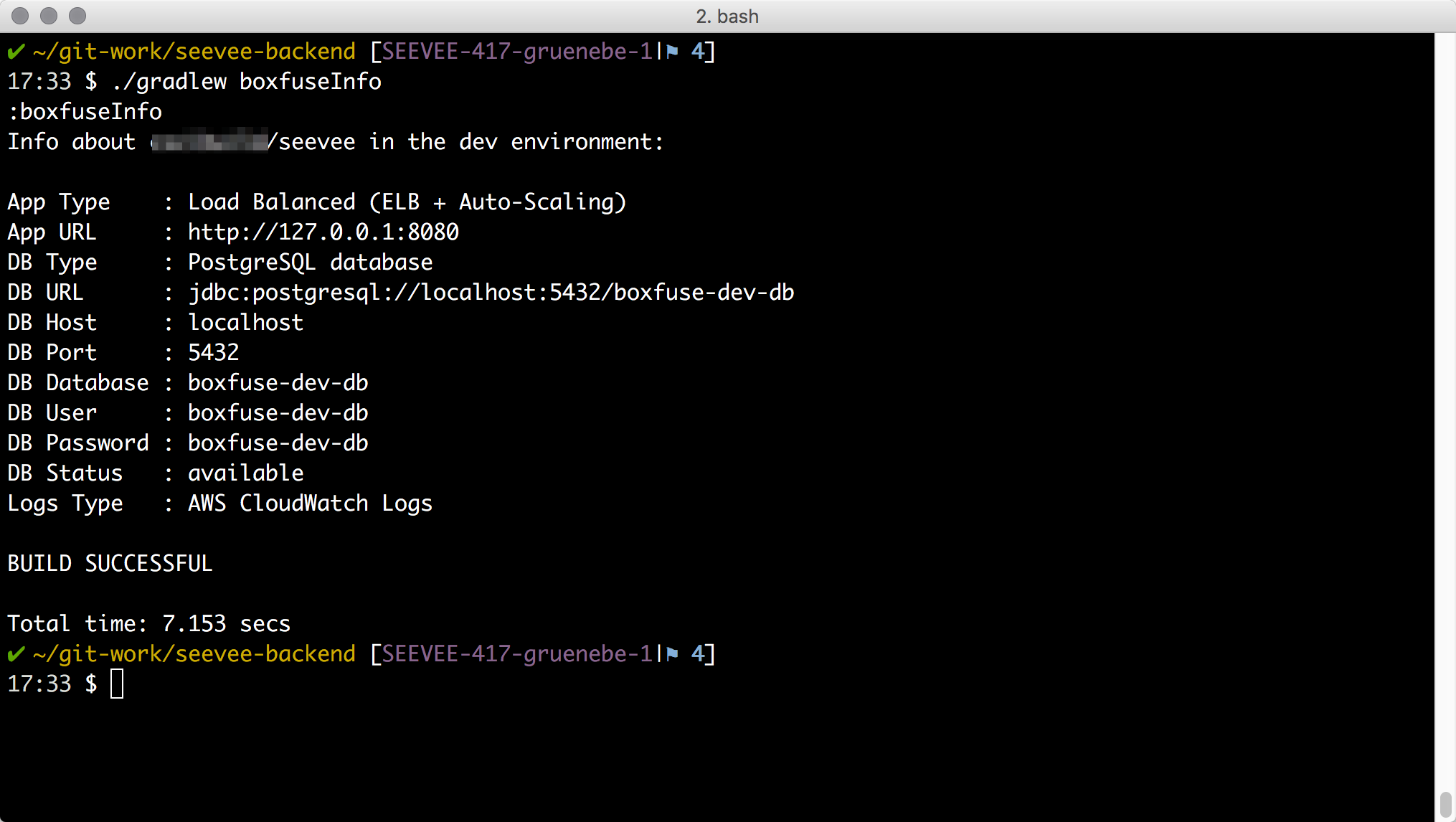
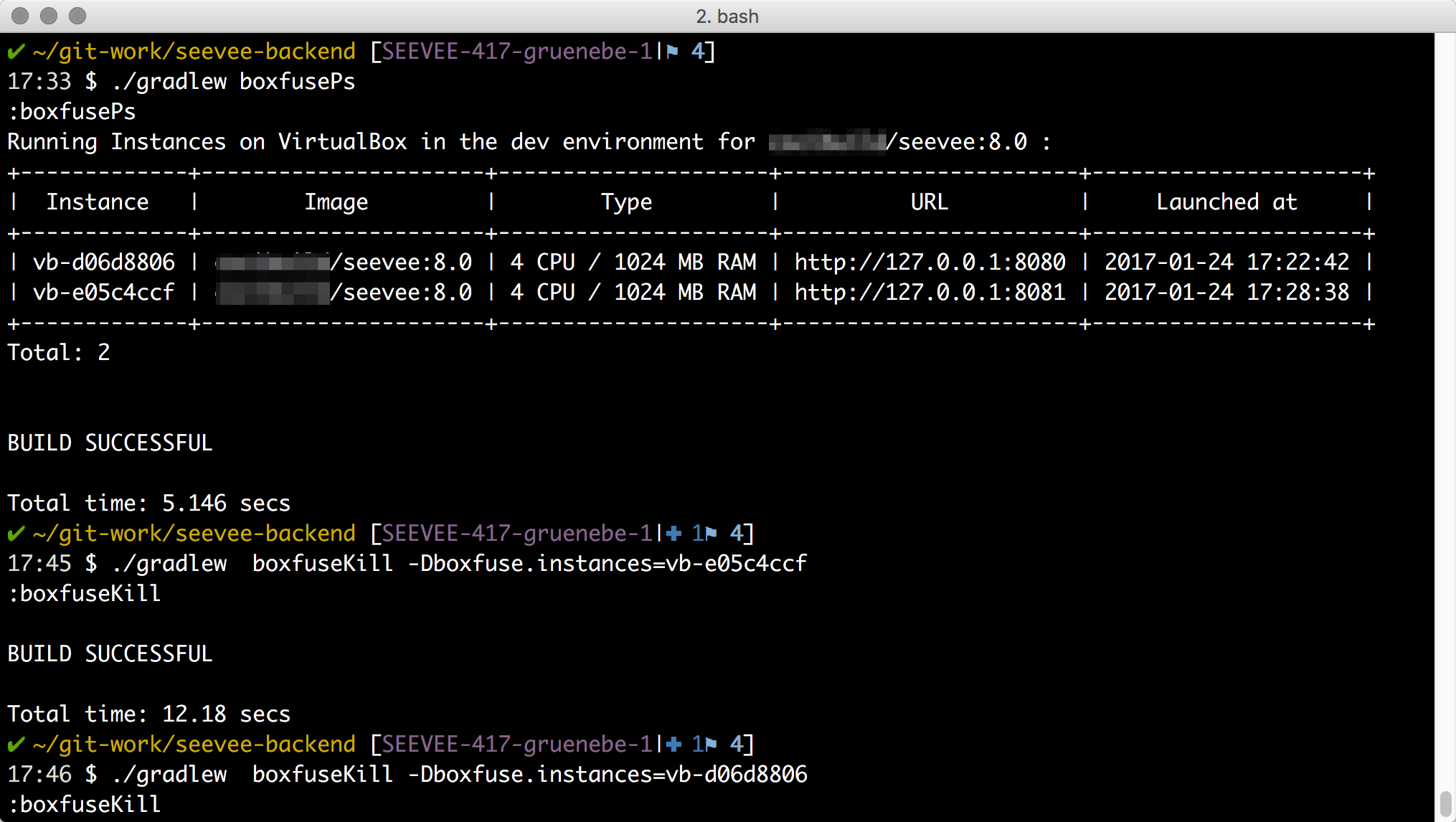
Da ich aus versehen zwei Instanzen gestartet habe will ich diese wieder terminieren. Da hilft boxfusePs und boxfuseKill.
Als ich das erste mal die Anwendung hochfahren wollte, war auf der Ausgabe so etwas wie ‘Port 8080 available’ aber es tat sich nichts, keine Logausgabe - Nichts. Ein curl ergab ‘Empty Response’ und dann schaltete ich mal wieder den ‘–debug’ beim boxfuseRun ein musste folgendes feststellen.
github:1d3b0d98e55d0545d70f8cc084270140
Die Instanz hat in Endlosschleife durchgestartet und ist immer wieder an der Flyway Migration gescheitert, da V18 wohl einen Syntax Fehler hat. Komisch, denn es lief bisher lokal durch. Aber wir versuchen das mal zu Debuggen und schalten uns mit dem folgenden Befehl auf die lokale Datenbank, welche durch Boxfuse hochgefahren wurde.
shell:./gradlew boxfuseOpen -Dboxfuse.db=true -Denv=test
Natürlich müssen wir dazu vorher einen PostrgeSQL-Client lokal installiert haben, was wir mit dem Homebrew-Befehl ‘brew install postgres’ bereits getan haben. Nachdem wir nun erfolgreich draufgeschaltet sind geben wir ‘\dt’ ein und sehen die Datenbank-Tabellen.
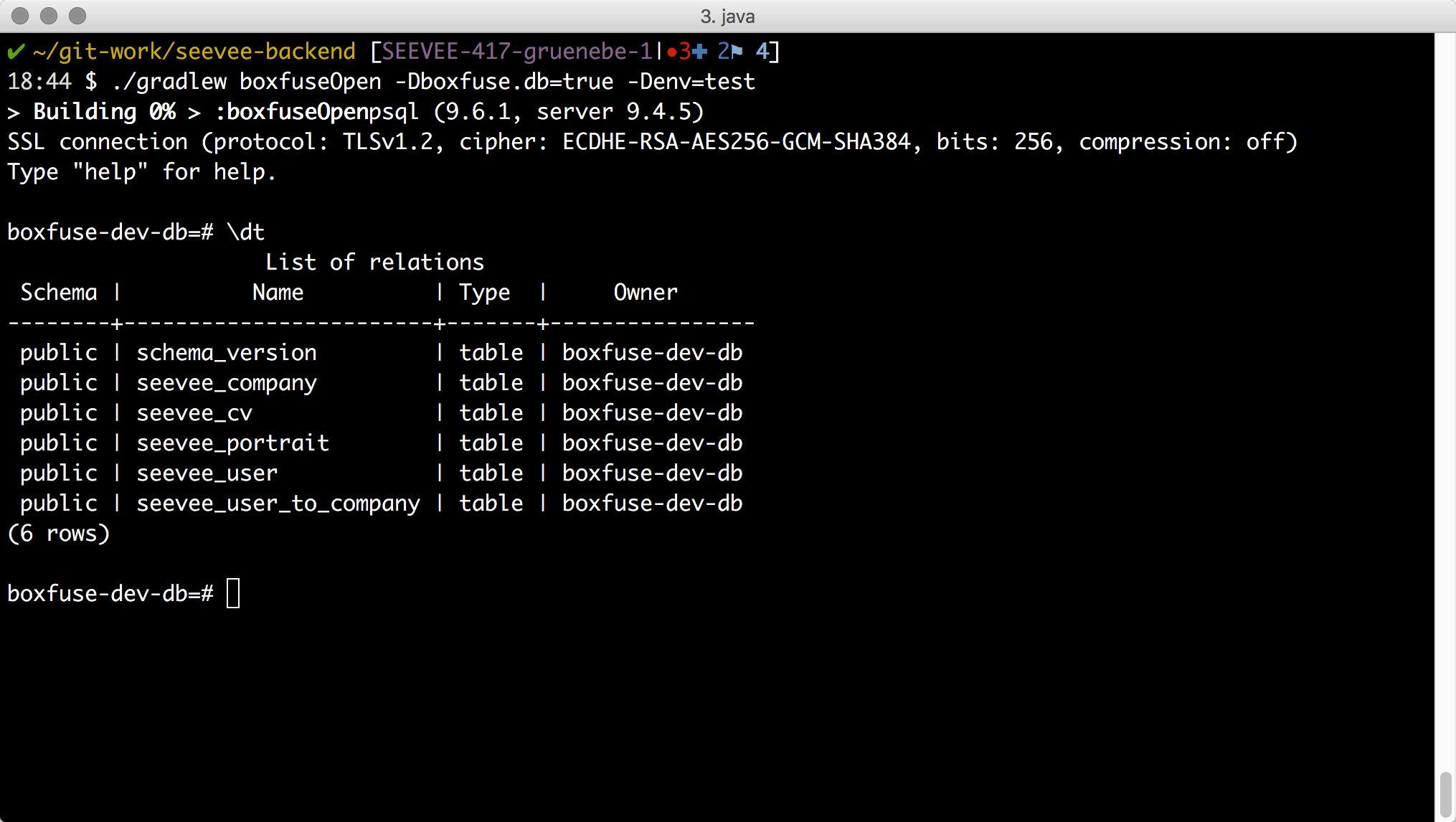
Die Tabellen sind da, also führen wir mal unser Statement aus der V18 Migration manuell aus.
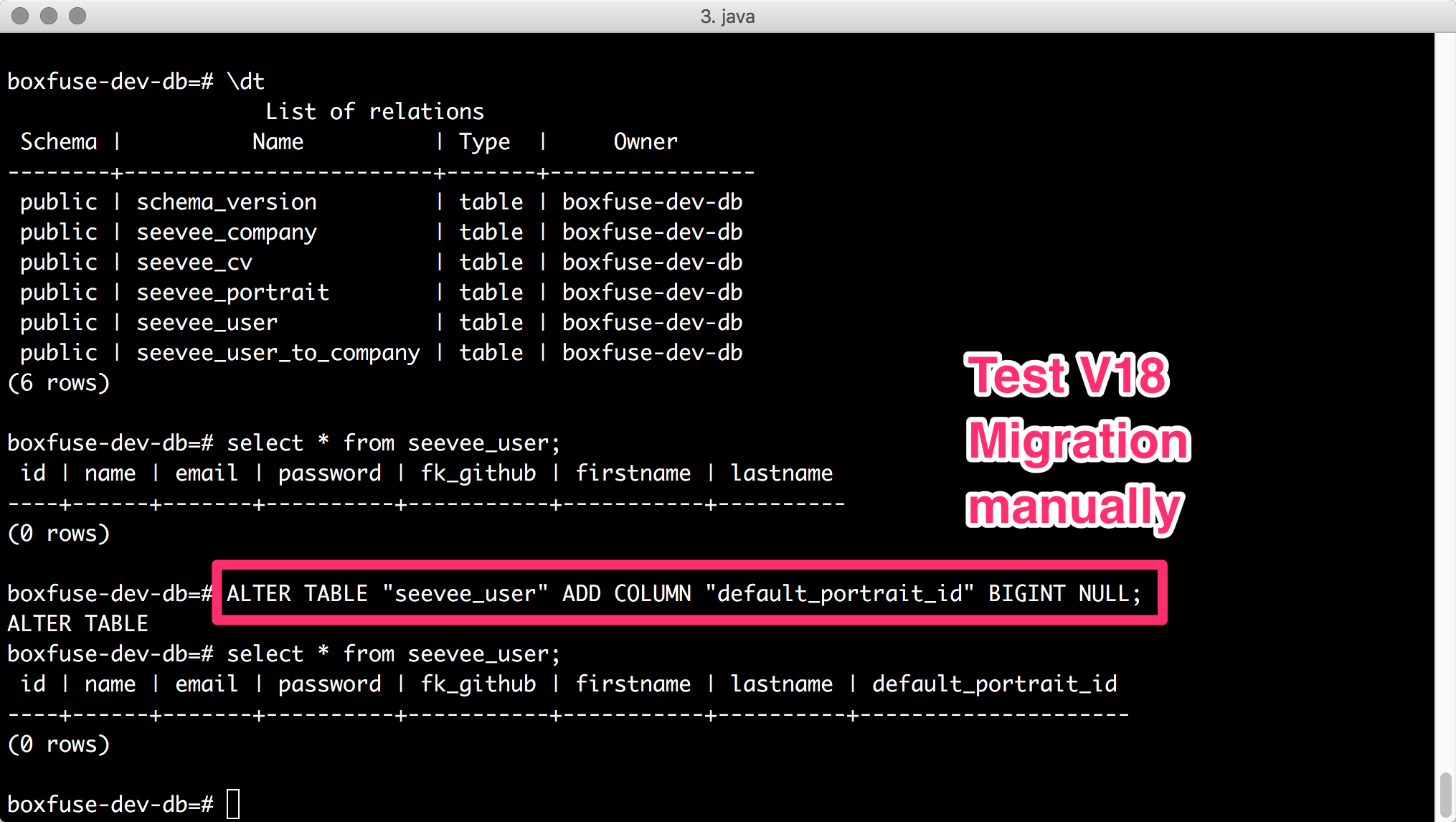
Ok - obwohl der Befehl so manuell ausführbar war stört sich die PostgreSQL Version an dem gequoteten Spalten-Namen, also ändern wir das Migrations-Skript wie folgt ab, machen ein ‘./gradlew clean build’ und starten boxfuseRun nochmal neu.
github:68949dc779781b997e3a452975d086ce
Nun fährt alles sauber hoch und ich bekomme für meinen Test-curl auch das erwartete Ergebnis.
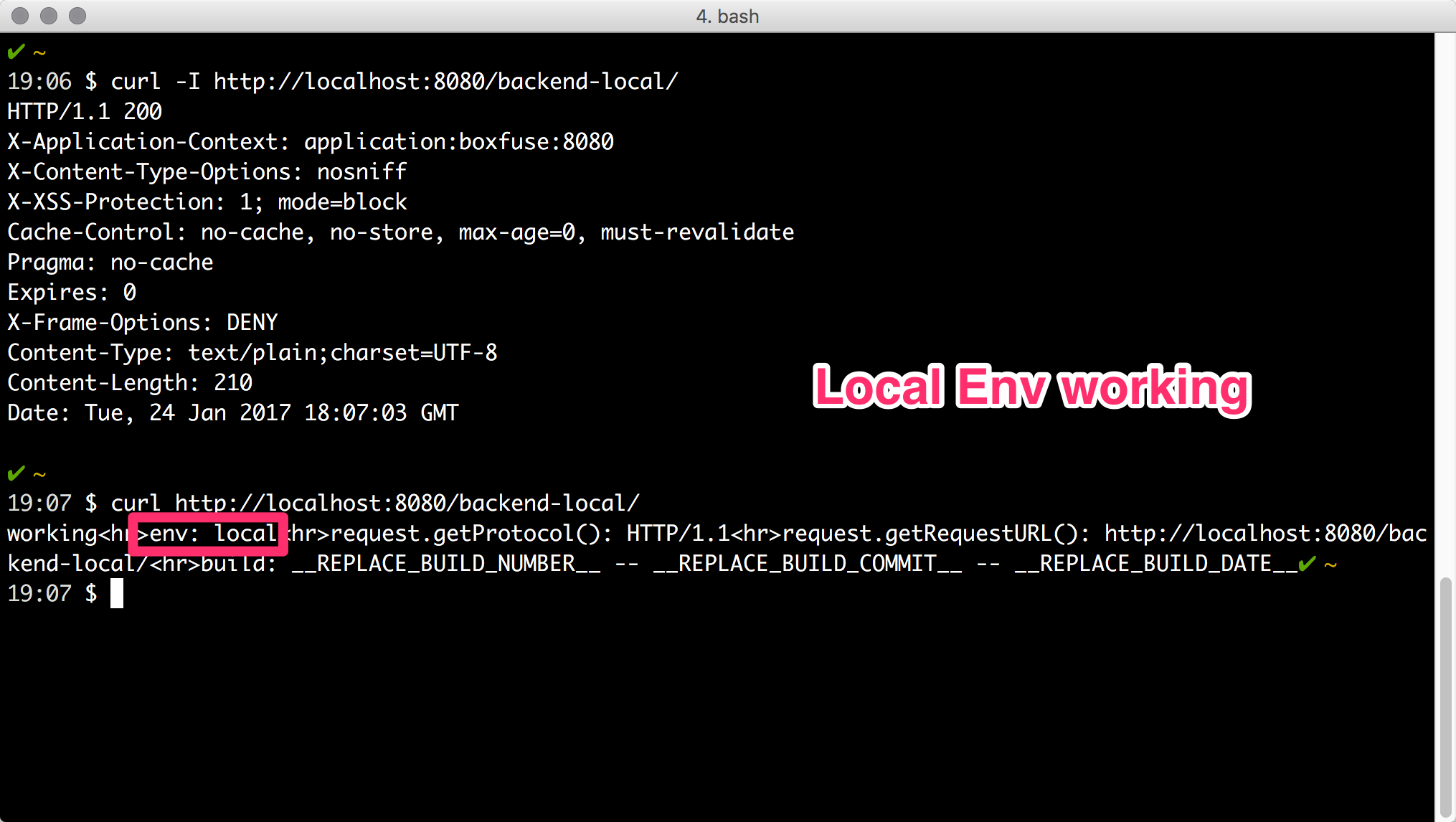
Wunderbar - besser hätte es nicht laufen können, denn jetzt wissen wir uns auch zu helfen, wenn wir mal Mist bauen und Syntax-Fehler in unsere Migrations-Skripte einbauen.
Aber was ist jetzt eigentlich genau passiert und was bedeutet das im größeren Zusammenhang? Ohne die unveränderbare Infrastruktur bereitgestellt von Boxfuse hätten wir diesen Fehler erst auf dem Test-Environment festgestellt, was für Rückkopplungen im Entwicklungsprozess gesorgt und evtl. das Sprint Goal unseres Scrum Prozesses gesprengt hätte. Bevor wir Boxfuse genutzt haben, hatte jeder Entwickler eine nicht-deterministische PostgreSQL Datenbank Installation auf seiner lokalen Workstation. Nehmen wir an ein Windows Entwickler testet das Migrations-Skript gegen seine lokale PostgreSQL-DB - es funktioniert lokal - scheitert dann aber auf dem Test-Environment oder noch schlimmer erst später auf dem Prod-Environment. Wir vermeiden mit Boxfuse also das klassische Works-On-My-Machine-Paradigma und schaffen deterministische Rahmenbedingungen, unter denen die Fehlersuche und Fehlerbehebung einfacher ist und man sich sicher sein kann, dass wenn etwas auf dem Dev-Environment funktioniert, es auch auf dem Test- und Prod-Environment funktioniert.

ITERATION 2: BACKEND AUTOMATISIERT IN DIE STAGINGUMGEBUNG DEPLOYEN
In der zweiten Iteration wollen wir das SeeVee-Backend mit Boxfuse auf die Stagingumgebung deployen, PhantomJS und Imagemagick bereitstellen und das Wildcard-SSL-Zertifikat einbinden, sodass wir am Ende der Iteration einen Self-Contained-Service (SCS) deployed haben.
Boxfuse stellt ein Standardprozedere bereit welches drei Environments vorsieht, welche eine Anwendung durchläuft bis sie letztlich auf der Produktivumgebung landet.

Damit wir nicht immer den Gradle-Wrapper bemühen müssen, laden wir uns den personalisierten Boxfuse-Client herunter und entpacken ihn nach ‘~/boxfuse’ und legen uns in unserer ‘.bashrc’ folgenden Alias an:
github:0694fcd187ddfe0cde03efd10caa795c
Jetzt können wir einfach ‘boxfuse ps’ und ‘boxfuse kill’ ausführen ohne Gradle bemühen zu müssen. Das geht für die beiden Befehle dann auch um einiges schneller.
Wir bauen unsere Anwendung seit jeher mit Jenkins und haben dazu ein einfaches Bash-Skript namens ‘jenkins.sh’ welches ausgeführt wird wenn ein GIT-PUSH auf das Repository des Backend geschieht. Es genügt daher folgende Anpassung vorzunehmen, damit das Backend mit Boxfuse gebaut, in den Boxfuse-Vault gepushed und letztlich in die Stagingumgebung deployed wird.
Zuerst passen wir unsere ‘build.gradle’ so an, dass später der Jenkins die ‘Patch-Version’ durch die laufende Jenkins-Build-Nummer ersetzen kann.
github:6fe7a087d1b2d0249404457f7a3f5b0a
In der ‘jenkins.sh’ geben wir als Ziel die Stagingumgebung mit ‘boxfuse.env=test’ an. Mittels ‘sed’ ersetzen wir in der Version die ‘Patch-Version’ durch die Jenkins-Build-Nummer.
github:3dac894debc210c46ff7104e6a66dd31
Nachdem wir diese Änderung im develop-Branch committed, gepushed und den Jenkins-Build abgewartet haben, ist das SeeVee-Backend erfolgreich deployed. Die ‘seevee-backend’ Seite in Boxfuse zeigt uns nun die deployte Version nun wie folgt an. Wir haben Version 8.2.1.37 im Boxfuse-Vault und auf ‘test’ deployed.
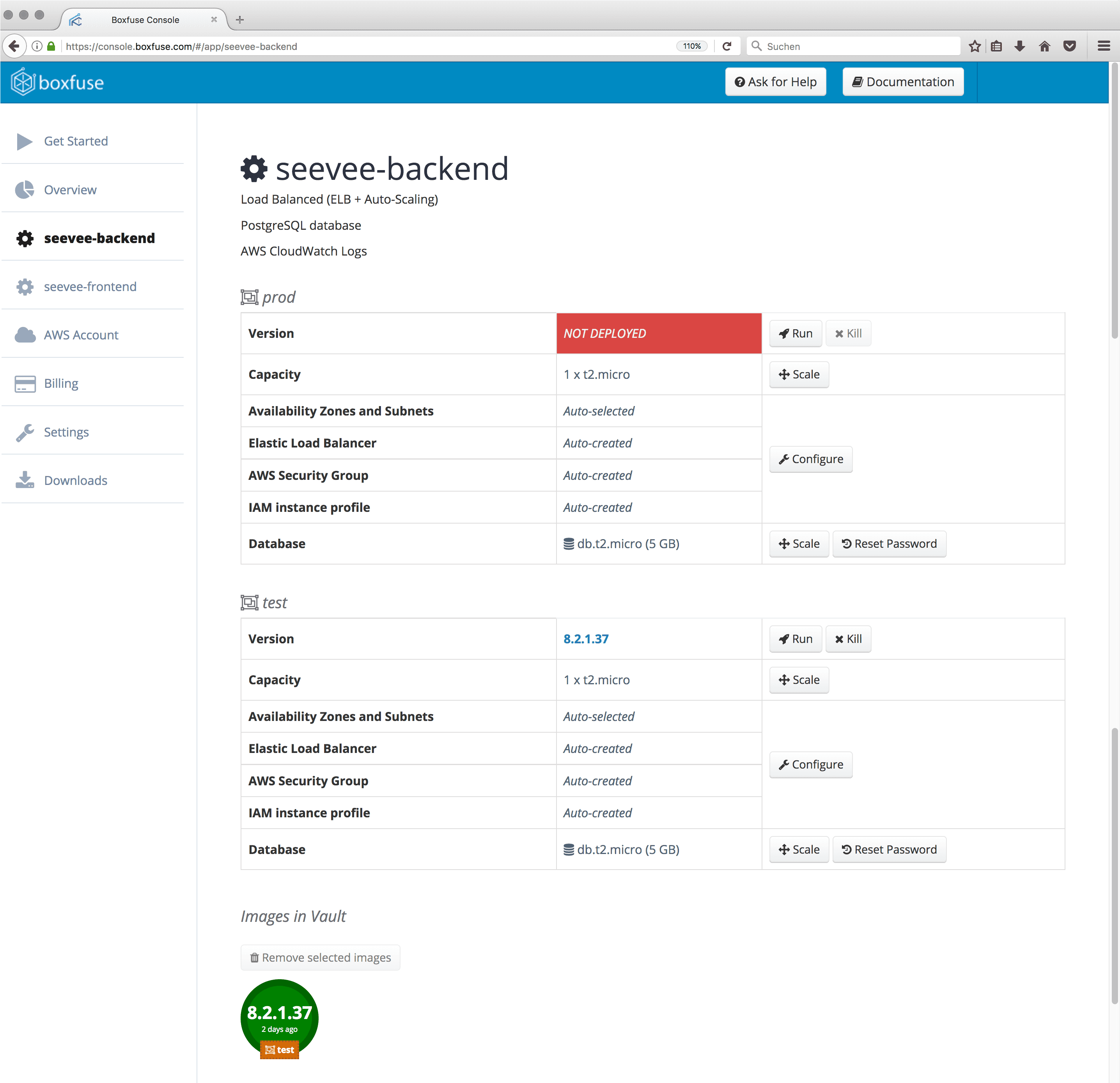
Nun wollen wir mit einem CURL natürlich überprüfen, ob die Anwendung uns antwortet. Die URL setzt sich dabei per Convention-Over-Configuration zusammen: ‘Anwendung + Environment + User . boxfuse.io : Port’.
shell:curl -s http://seeveebackend-test-cscibuild.boxfuse.io:8080/ | jq '.'
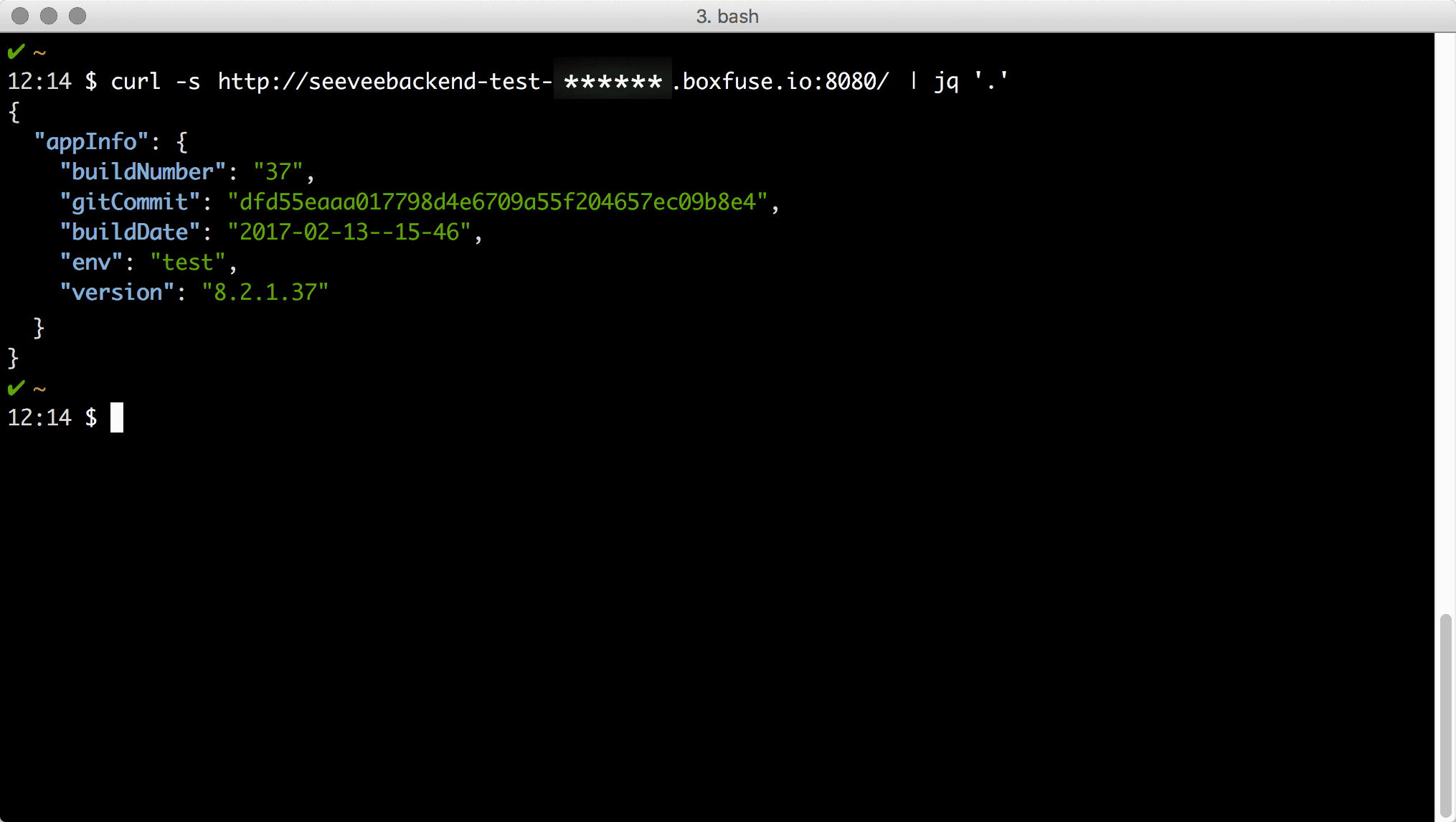
Wir haben uns dafür extra einen ‘HomeController’ geschrieben, welcher uns eine JSON-Ausgabe liefert und alle wichtigen Informationen enthält, sodass wir sofort erkennen können, ob auch wirklich re-deployed wurde. Die Ausgabe gibt an ‘env: test’ und ‘version: 8.2.1.37’ was uns zeigt, dass wir das SeeVee-Backend nun erfolgreich auf der Stagingumgebung deployed haben.
Nach diesem Erfolg machen wir uns umgehend an die Umstellung auf HTTPS mit einem Wildcard-SSL-Zertifikat. Dazu müssen wir aber zuerst im DNS CNAME-Einträge und A-Einträge anlegen, da unser Wildcard-SSL-Zertifikat auf ‘⋆.seevee.io’ ausgestellt ist.

Nachdem wir die Domains für alle Environments eingerichtet haben legen wir unser SSL-Zertifikat im JKS Format nach ‘src/main/resources/’ und richten folgendes in unserer ‘application-boxfuse.yml’ ein, sodass unsere SpringBoot Anwendung anstatt auf TCP Port 8080 auf TCP Port 443 hört und mit HTTPS arbeitet.
github:edb01ec26da80f69c886408b229dc52e
Bevor wir unsere Code-Changes committen und pushen müssen wir noch über die AWS-Console den EC2 Elastic Loadbalancer anpassen, den Listen-Port auf TCP 443 umstellen und den Health-Check anpassen. Das tun wir wie in den folgenden Screenshots dargestellt.

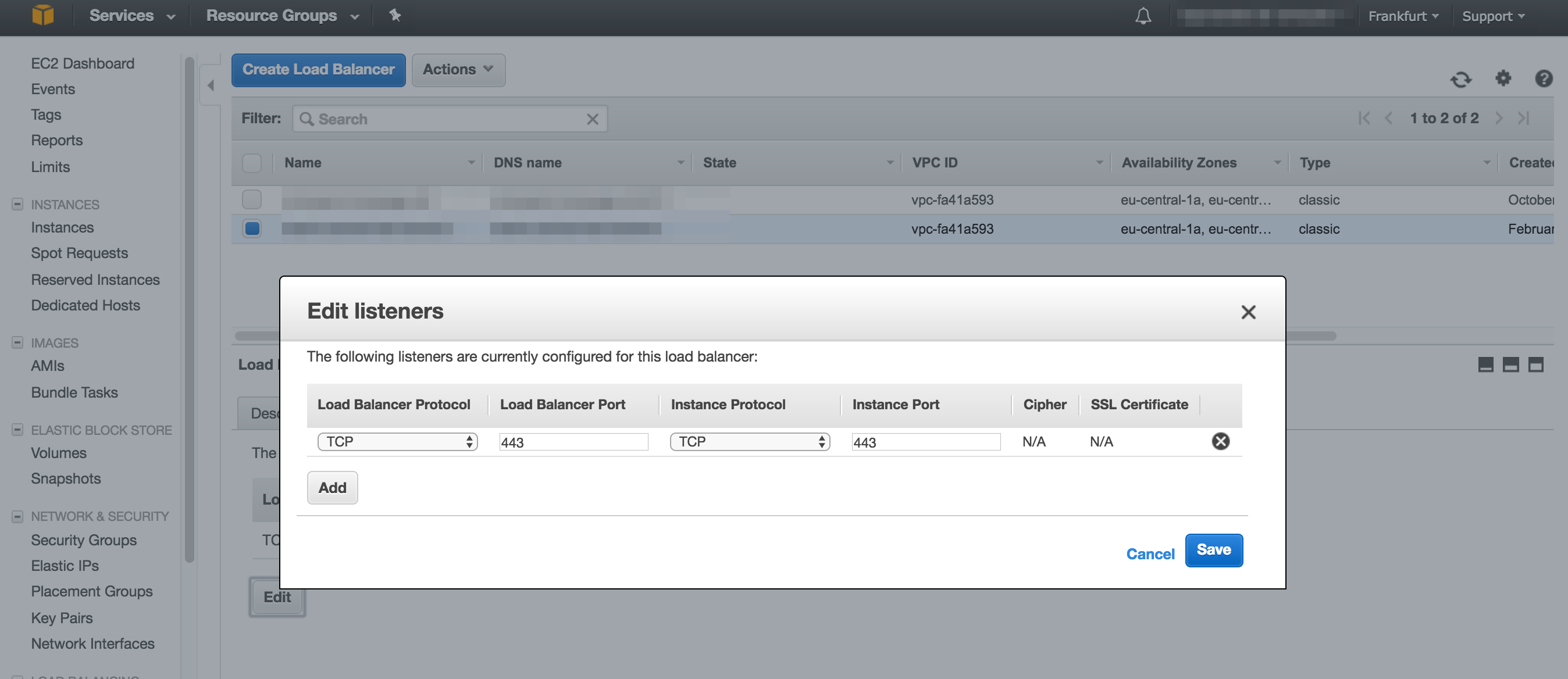
Der ‘/health’ Endpoint wird von SpringBoot per default bereitgestellt. Da wir bei uns aber alle Metriken und magic-Endpoints von SpringBoot deaktiviert haben, haben wir einfach manuell einen RestController angelegt der auf ‘/health’ horcht und HTTP 200 zurück gibt.
Nachdem wir den ELB eingestellt haben und unsere Changes gepushed haben können wir einen Test-CURL mit HTTPS auf unsere Custom-Domain machen.
shell:curl -s https://backend-test.seevee.io/ | jq '.'
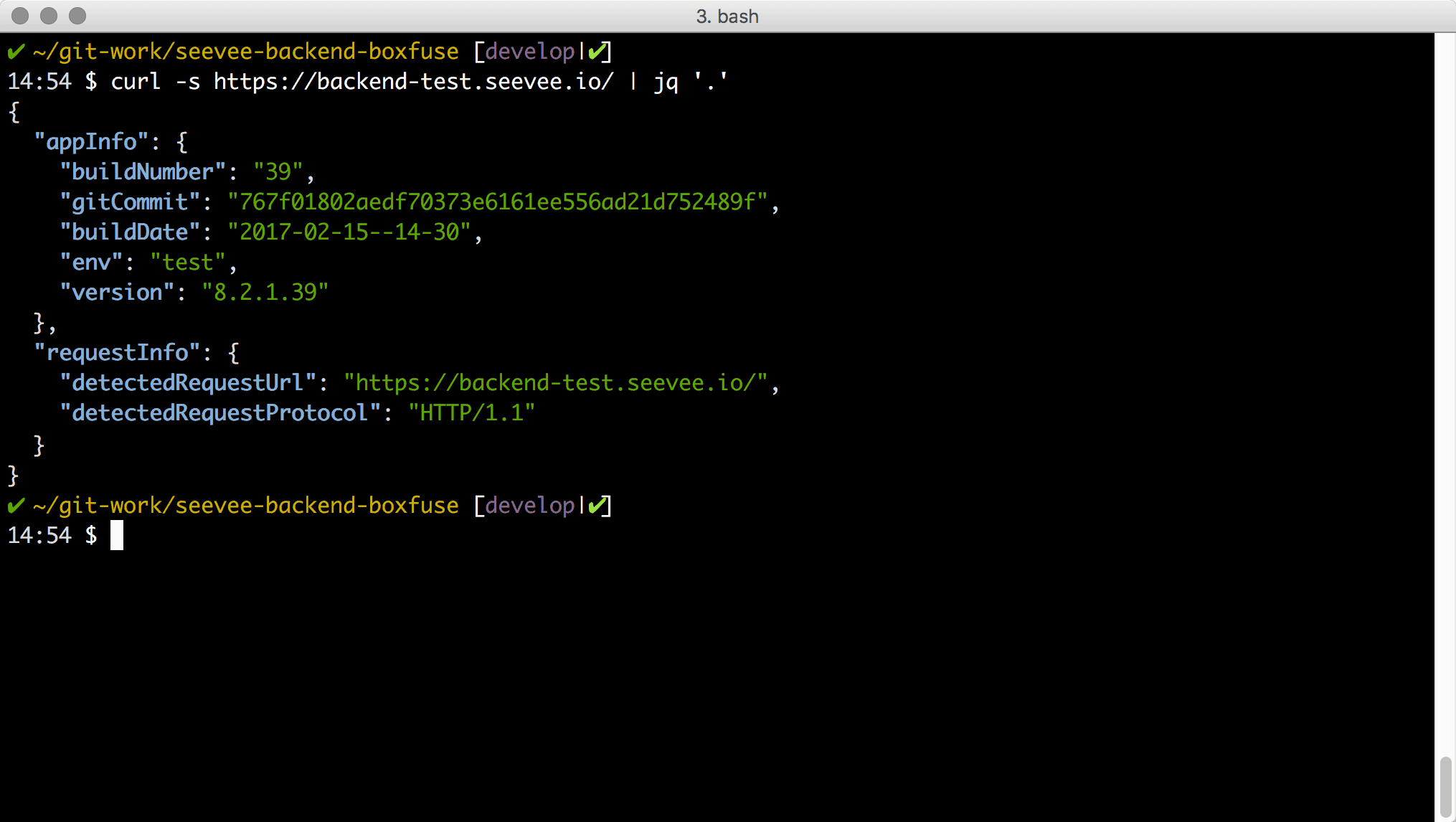
Da wir ja auch ‘backend-dev.seevee.io’ auf 127.0.0.1 zeigend eingerichtet haben, können wir das Backend auch lokal starten und mit dem Wildcard-SSL-Zertifikat geschützt aufrufen. Wir haben dazu wieder mit ‘./gradlew boxfuseRun’ das Backend gestartet und können nun den CURL ausführen. Einzige Besonderheit ist, dass lokal TCP Port 10443 verwendet wird, was sich aber leicht mit ‘boxfuse ps’ herausfinden lässt.
shell:curl -s https://backend-dev.seevee.io:10443/ | jq '.'
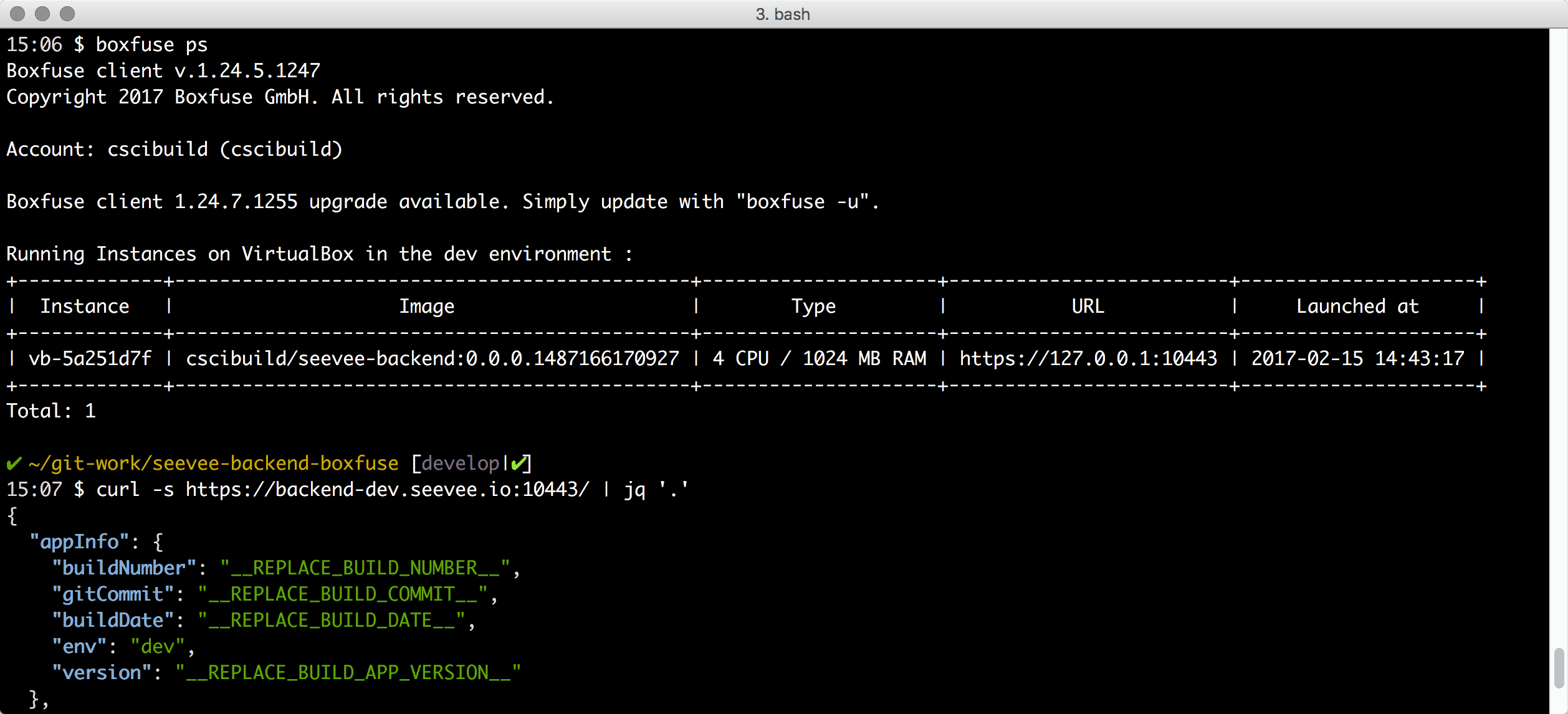
Da wir nun unsere Anwendung mit SSL (TLS) geschützt haben können wir uns um Bereitstellung der Native-Libs PhantomJS und Imagemagick kümmern. Boxfuse baut uns ein Basis Amazon Machine Image (AMI) mit einem Linux-Kernel und glibc. Mehr ist nicht drin und mehr brauchen wir auch nicht. Baut Boxfuse unser Backend legt es noch OpenJDK mit ins Image hinein. Das geschieht alles automatisch und ist sehr komfortabel. Da wir aber nun PhantomJS und Imagemagick innerhalb dieses Images nutzen wollen, müssen wir Boxfuse mitteilen, wo es die Dateien finden kann, sodass er sie während des Bauens in das Image kopiert und im $PATH bereitstellt.
Glücklicherweise hat Boxfuse dafür bereits eine Konvention. Die Binaries kommen nach ‘/src/main/resources/native/bin/’ und die Bibliotheken nach ‘/src/main/resources/native/lib/’. Das beste Vorgehen, um an diese Dateien heranzukommen, ist es sich ein Virtuelles Ubuntu 16.04 64 Bit zu installieren, die Anwendung zu installieren und letztlich die Binaries inklusive Bibliotheken von dort zu kopieren.
Ich zeige es jetzt anhand Imagemagick, für PhantomJS funktioniert es analog. Zuerst installieren wir Imagemagick.
shell:apt-get install imagemagick
Wir haben es auf die ‘convert’-Binary abgesehen und untersuchen daher welche Bibliotheken von ‘convert’ genutzt werden.
shell:which convert
shell:ldd /usr/bin/convert
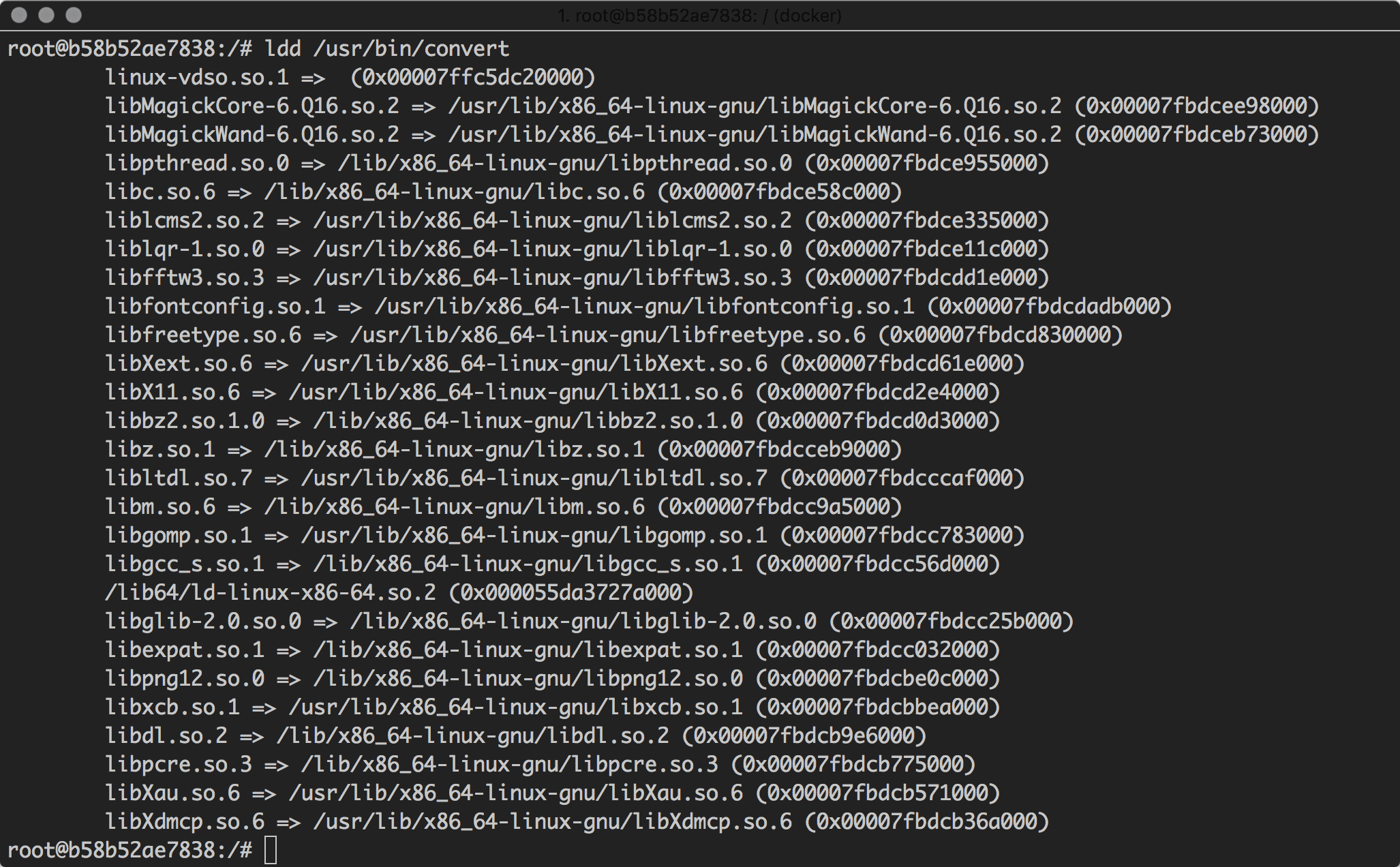
Wir kopieren nun ‘/usr/bin/convert’ und alle uns aufgelistetenen Bibliotheken in unser SpringBoot Projekt. Dasselbe tun wir für PhantomJS. Anschließend passen wir unseren HomeController so an, dass es er uns die Versionsausgabe der Binaries anzeigt.
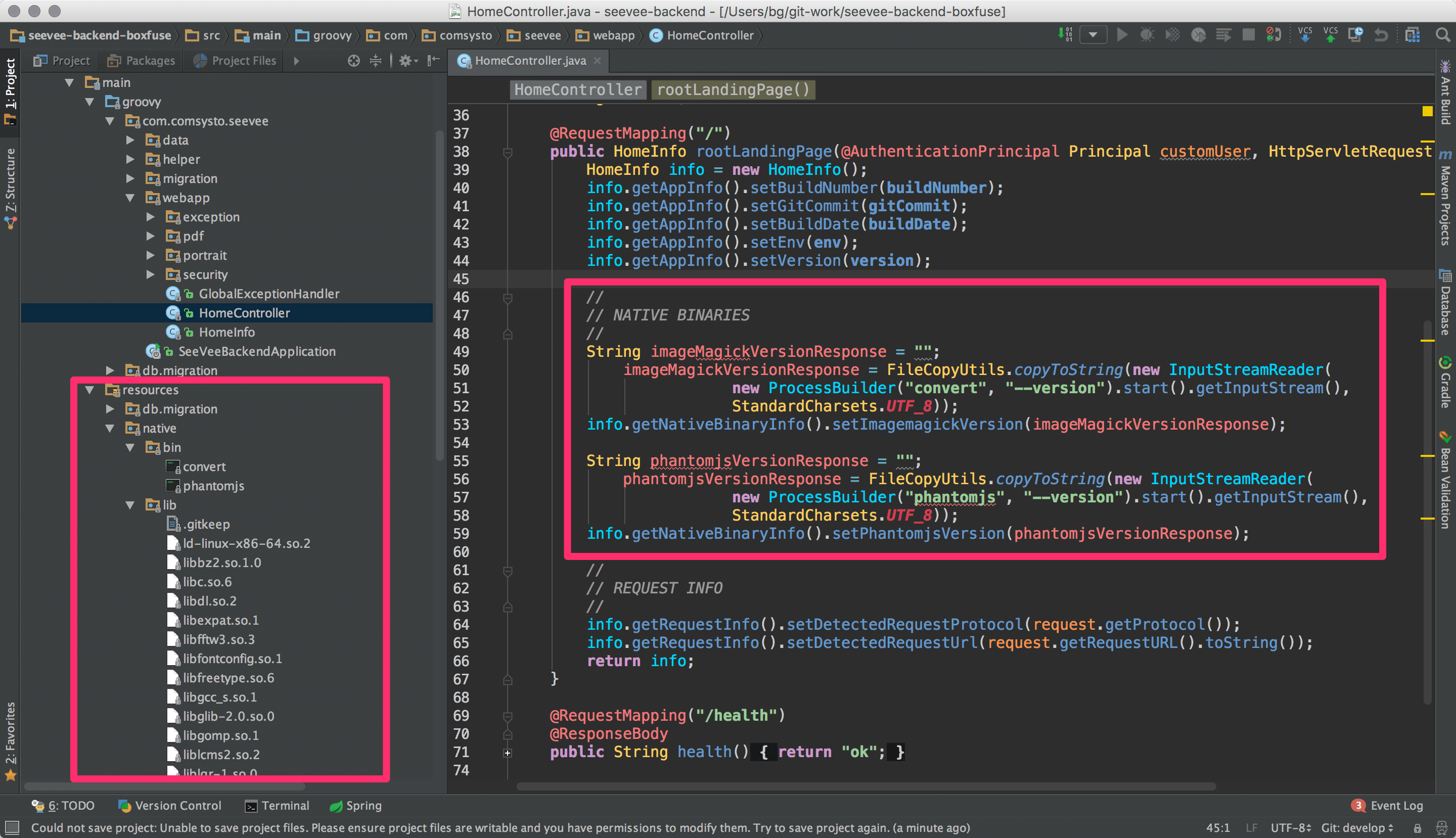
Nach dem commit, push und redeploy sehen wir das Ergebnis mit folgendem Test-CURL.
shell:curl -s https://backend-test.seevee.io/ | jq '.'
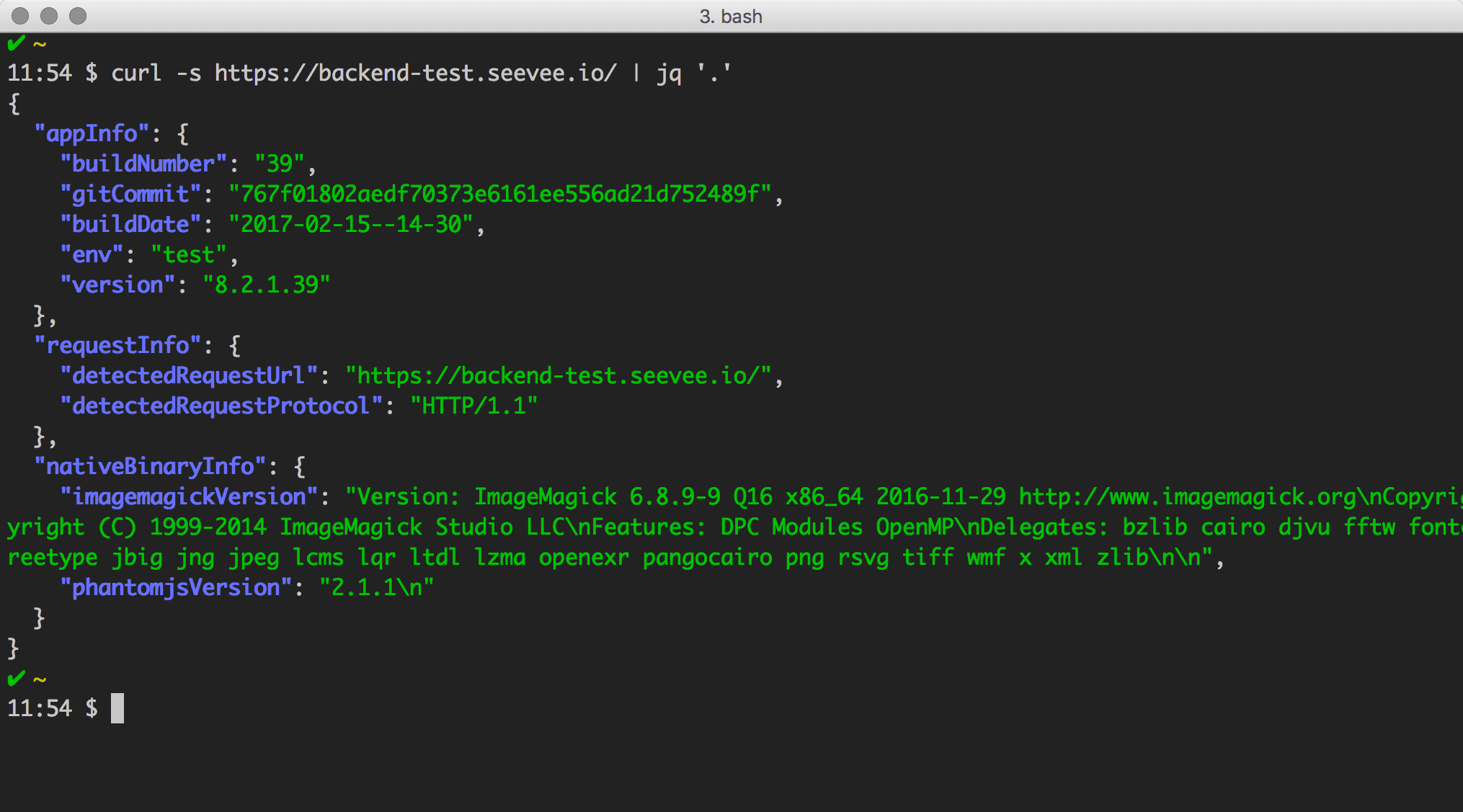
Wir sind fertig mit allem, was wir uns für diese Iteration vorgenommen haben, schauen uns unsere Infrastruktur-Anforderungen an und haken die erledigten Dinge mit Freuden ab.

FAZIT UND AUSBLICK
Wir haben gezeigt, wie schnell und einfach man mit Boxfuse unveränderbare Infrastruktur nutzen und ohne viel Aufwand Self Contained Services deployen kann. Von Seiten der Infrastruktur haben wir bereits alles umgesetzt, damit das SeeVee-Backend mit Boxfuse lauffähig ist. Da wir aber Technical Debt aufgebaut haben, werden wir uns im Teil zwei der BlogPost-Serie um (BAF-7) kümmern und die Anwendung umschreiben, sodass sie mit dem Auto-Scaling und stateless-Loadbalancing umgehen kann. In Teil drei der BlogPost Serie nehmen wir uns dann dem SeeVee-Frontend an. Damit Sie auch die weiteren Teile der BlogPost-Serie nicht verpassen, melden Sie sich am besten zu unserem Newsletter an - scrollen Sie dazu ganz nach unten und tragen Sie sich in das entsprechende Formular ein.
Wenn auch Sie Ihre Dienste mit Boxfuse betreiben wollen und alle Vorteile von unveränderbarer Infrastruktur nutzen wollen, untersützen wir Sie gerne. Wir können in Workshops oder projektbegleitendem Coaching Ihre Mitarbeiter im Umgang mit Boxfuse schulen oder auch gemeinsam mit Ihnen Ihre Infrastruktur migrieren. Mehr Details finden Sie unter Architektur & Entwicklung. Wir freuen uns über eine Kontaktaufnahme, gerne auch ganz formlos über das unten angezeigte Kontaktformular.